介绍
得益于了 Go 运行时高效的内置内存管理,我们通常能够在程序中优先考虑正确性和可维护性,而不需要过多考虑如何进行分配的细节。不过,有时我们可能会发现代码中的性能瓶颈,并希望进行更深入的研究。
任何使用 -benchmem 标志运行基准测试的人都会在输出中看到 allocs/op 的统计。在这篇文章中,我们将看看什么算作一个 alloc,以及我们可以做什么来影响这个数字。1
BenchmarkFunc-8 67836464 16.0 ns/op 8 B/op 1 allocs/op
我们熟悉和喜爱的栈和堆
要讨论 Go 中的 allocs/op 统计,我们将对 Go 程序中的两个内存区域感兴趣:栈和堆。
在许多流行的编程环境中,栈通常指的是线程的调用栈。调用栈是一个先进先出(LIFO)栈数据结构,它存储了线程执行函数时跟踪的参数、局部变量和其他数据。每一次函数调用都向栈增加(推)一个新的帧,每一次返回函数都会从栈中删除(弹出)。
我们必须能够在最近的栈帧被弹出时安全地释放它的内存。因此,我们不能在栈上存储任何以后需要在其他地方引用的东西。

由于线程是由操作系统管理的,所以线程栈的可用内存量通常是固定的,例如在许多 Linux 环境中默认为 8MB。这意味着我们还需要注意栈上最终有多少数据,特别是在嵌套较深的递归函数的情况下。如果上图中的栈指针通过了栈保护,程序就会因栈溢出错误而崩溃。
堆是内存中更复杂的区域,与同名的数据结构没有关系。我们可以按需使用堆来存储程序中需要的数据。在这里分配的内存不能在函数返回时简单地释放,需要仔细管理,以避免泄漏和碎片化。堆通常会比任何线程栈大许多倍,任何优化工作的大部分时间都将花费在研究堆的使用上。
Go 栈和堆
由操作系统管理的线程被 Go 运行时完全抽象出来,我们使用的是一个新的抽象:goroutines。goroutine 在概念上与线程非常相似,但它们存在于用户空间中。这意味着是运行时而不是操作系统来设置栈的行为规则。
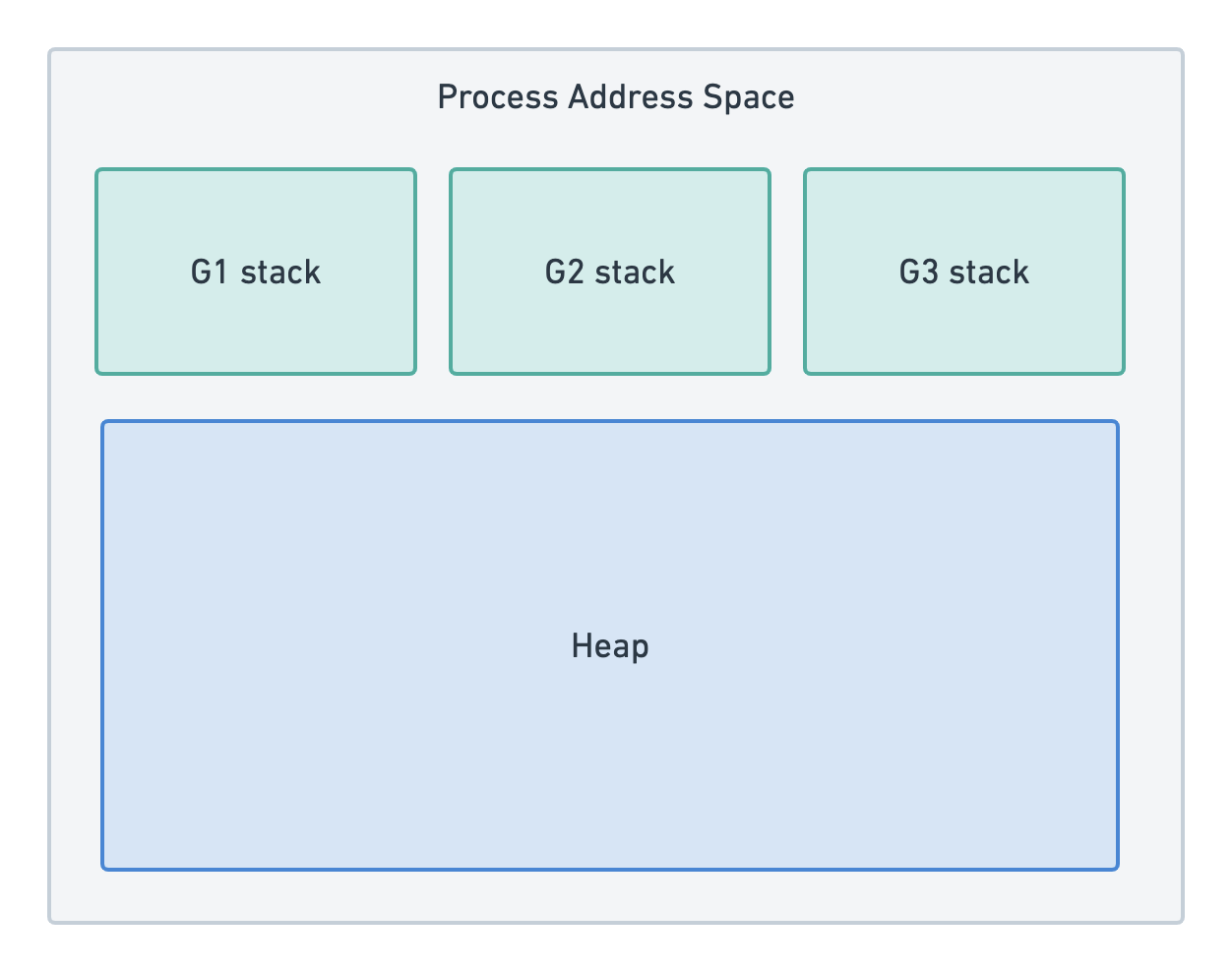
goroutine 栈并不是由操作系统设置的硬性限制,而是以少量的内存(目前为 2KB)开始。在执行每个函数调用之前,在函数序言中会执行检查,以验证不会发生栈溢出。在下面的图中,convert() 函数可以在当前栈大小的限制下执行(在 SP 不超额处理 stackguard0 的情况下)。
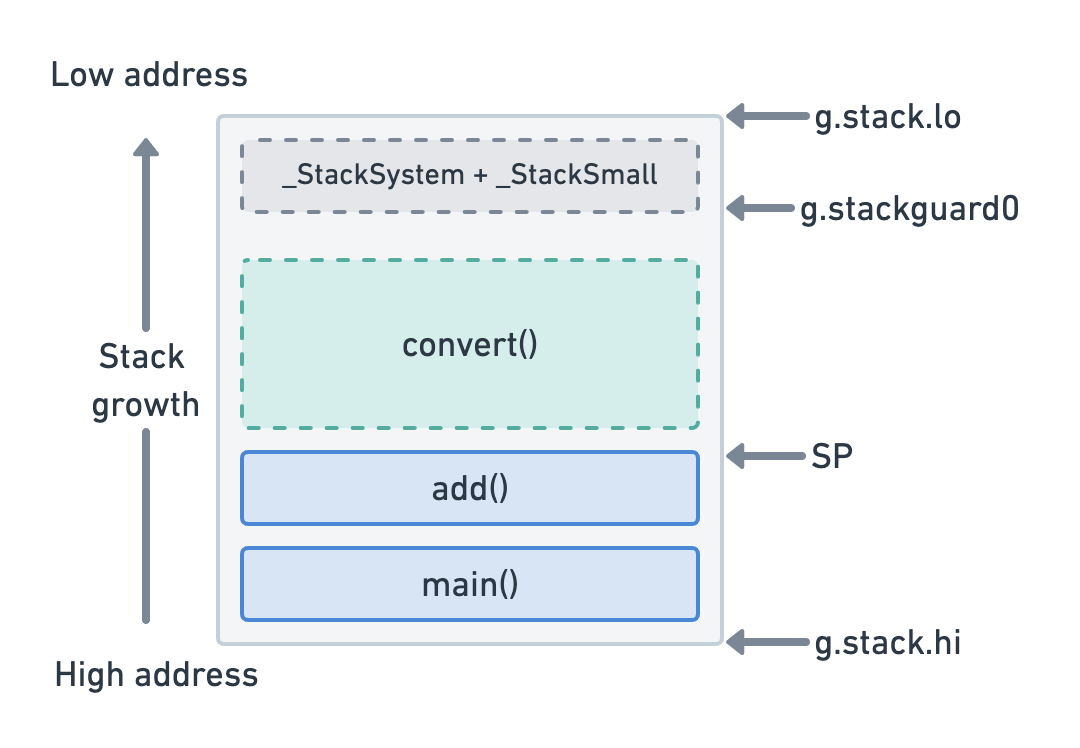
如果不是这样,运行时将在执行 convert() 之前将当前栈复制到一个更大的连续内存空间中。这意味着 Go 中的栈是动态大小的,只要有足够的内存可用,通常就可以保持增长。
Go 堆在概念上同样类似于上面描述的线程模型。所有的 goroutines 共享一个公共堆,任何不能存储在栈上的东西都将在那里结束。当对函数进行基准测试时发生堆分配时,我们将看到allocs/ops 属性增加 1。垃圾回收器的工作是稍后释放不再引用的堆变量。
关于Go中如何处理内存管理的详细解释,请参阅 从头开始的 Go 内存分配器的可视化指南。
我们如何知道一个变量何时被分配给堆?
这个问题答案在官方 FAQ 中。
Go 编译器将为函数的栈帧中分配该函数的局部变量。但如果编译器不能证明该变量在函数返回后没有被引用,那么编译器必须在垃圾回收的堆上分配变量,以避免指针悬空错误。而且,如果局部变量非常大,那么将它存储在堆上而不是栈上可能更有意义。
如果某个变量的地址已被占用,那么该变量将成为堆上分配的候选变量。然而,一个基本的转义分析可以识别出一些情况,即这样的变量不会活过函数的返回,可以驻留在栈中。
由于编译器的实现会随着时间的推移而改变,所以仅仅通过阅读 Go 代码,是无法知道哪些变量会被分配到堆中的。不过,可以在编译器的输出中查看上面提到的 escape 分析结果。这可以通过传递给 go build 的 gcflags 参数来实现。完整的选项列表可以通过 go tool compile -help 来查看。
对于转义分析结果,可以使用 -m 选项(打印优化决策)。让我们用一个简单的程序来测试一下,为函数 main1 和 stackIt 创建两个栈帧。1
2
3
4
5
6
7
8func main1() {
_ = stackIt()
}
//go:noinline
func stackIt() int {
y := 2
return y * 2
}
因为如果编译器删除了函数调用,我们就无法讨论栈行为,所以在编译代码时使用 noinline pragma 来防止内联。让我们看一下编译器对其优化决策说些什么。-l 选项用于省略内联决策。1
2$ go build -gcflags '-m -l'
# github.com/Jimeux/go-samples/allocations
在这里,我们看到,没有做出任何关于逃跑分析的决定。换句话说,变量 y 保留在栈中,并没有触发任何堆分配。我们可以用基准测试来验证这一点。1
2$ go test -bench . -benchmem
BenchmarkStackIt-8 680439016 1.52 ns/op 0 B/op 0 allocs/op
正如预期的那样,allocs/op 统计值为 0。从这个结果中我们可以得到的一个重要观察是,复制变量可以让我们将它们保留在栈中,避免分配到堆中。让我们通过修改程序来验证这一点,以避免使用指针进行复制。1
2
3
4
5
6
7
8
9func main2() {
_ = stackIt2()
}
//go:noinline
func stackIt2() *int {
y := 2
res := y * 2
return &res
}
让我们看以下编译器的输出。1
2
3go build -gcflags '-m -l'
# github.com/Jimeux/go-samples/allocations
./main.go:10:2: moved to heap: res
编译器告诉我们,它把指针 res 移到了堆上,从而触发了堆分配,这在下面的基准中得到了验证。1
2$ go test -bench . -benchmem
BenchmarkStackIt2-8 70922517 16.0 ns/op 8 B/op 1 allocs/op
那么这是否意味着指针一定会创建分配?让我们再次修改程序,这次将指针传到栈下。1
2
3
4
5
6
7
8
9
10func main3() {
y := 2
_ = stackIt3(&y) // pass y down the stack as a pointer
}
//go:noinline
func stackIt3(y *int) int {
res := *y * 2
return res
}
然而运行基准测试显示没有任何东西被分配到堆中。1
2$ go test -bench . -benchmem
BenchmarkStackIt3-8 705347884 1.62 ns/op 0 B/op 0 allocs/op
编译器的输出明确地告诉我们这一点。1
2
3$ go build -gcflags '-m -l'
# github.com/Jimeux/go-samples/allocations
./main.go:10:14: y does not escape
为什么会出现这种看似不一致的情况呢?stackIt2 将 y 的地址从栈上传递到 main,在 main 中,y 将在 stackIt2 的栈帧被释放后被引用。因此,编译器能够判断 y 必须被移到堆上才能保持活力。如果它不这样做,当我们试图引用 y 时,就会在 main 中得到一个 nil 指针。
而 stackIt3 则是将 y 传到栈下,而且 y 在 main3 之外的任何地方都不会被引用。因此,编译器能够判断 y 可以单独存在于栈中,而不需要分配到堆中。在任何情况下,我们都无法通过引用 y 来产生一个 nil 指针。
从这里我们可以推断出一个通用规则,即在栈上共享指针会导致分配,而共享栈下的指针则不会。但是,这并不能保证,所以您仍然需要使用 gcflags 或基准来验证。我们可以肯定的是,任何试图减少 allocs/op 的尝试都将涉及到寻找任性的指针。
我们为什么要关心堆分配?
我们已经了解了一些关于 allocs/op 中的 alloc 的含义,以及如何验证是否触发了对堆的分配,但是为什么我们要关心这个统计是否是非零呢?我们已经做的基准测试可以回答这个问题。1
2
3BenchmarkStackIt-8 680439016 1.52 ns/op 0 B/op 0 allocs/op
BenchmarkStackIt2-8 70922517 16.0 ns/op 8 B/op 1 allocs/op
BenchmarkStackIt3-8 705347884 1.62 ns/op 0 B/op 0 allocs/op
尽管所涉及的变量对内存的需求几乎相等,但相对而言,BenchmarkStackIt2 对 CPU 的开销还是很明显的。我们可以通过生成 stackIt 和 stackIt2 生成的 CPU 曲线的火焰图来了解更多的情况。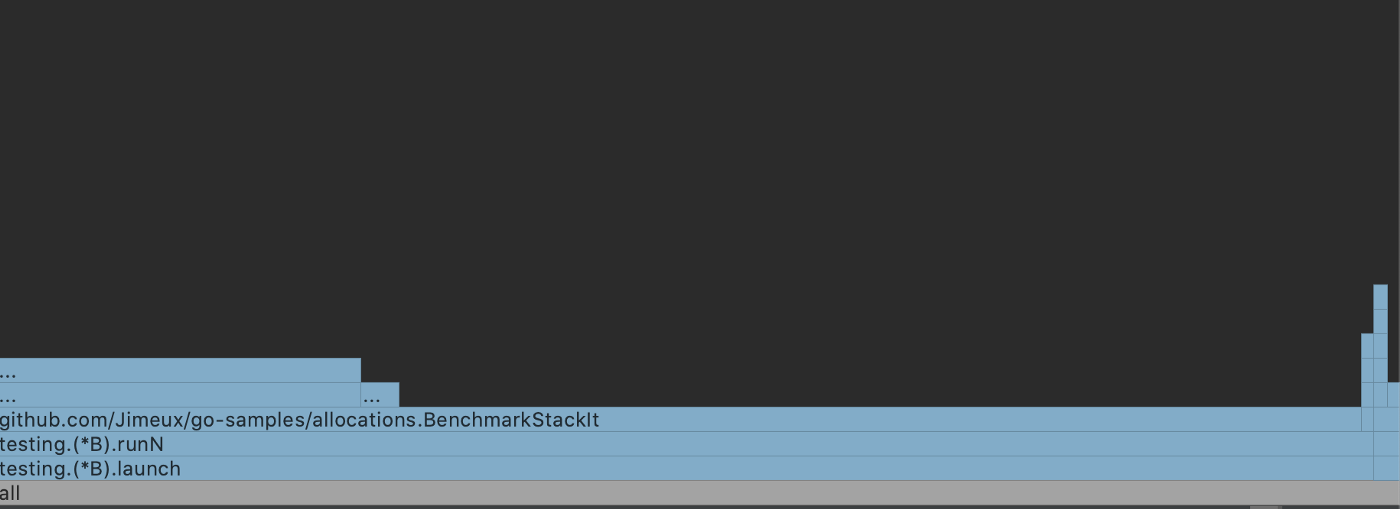

stackIt 有一个不起眼的配置文件,它可以预见地从调用栈运行到 stackIt 函数本身。另一方面,stackIt2 大量使用了大量的运行时函数,这些函数消耗了许多额外的 CPU 周期。这说明了分配到堆所涉及的复杂性,并初步了解了每个操作额外的 10 纳秒左右的去向。
那在现实世界中呢?
如果没有生产条件,性能的许多方面不会变得明显。你的单个功能可能在微基准测试中高效运行,但当它为成千上万的并发用户服务时,它会对你的应用程序有什么影响呢?
我们不会在这篇文章中重新创建一个完整的应用程序,但我们将使用跟踪工具来看看一些更详细的性能诊断。让我们首先定义一个(有点)大的结构体,它有 9 个字段。1
2
3
4
5type BigStruct struct {
A, B, C int
D, E, F string
G, H, I bool
}
现在我们来定义两个函数:CreateCopy,它在栈帧之间复制 BigStruct 实例;CreatePointer,它在栈上共享 BigStruct 指针,避免复制,但会产生堆分配。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//go:noinline
func CreateCopy() BigStruct {
return BigStruct{
A: 123, B: 456, C: 789,
D: "ABC", E: "DEF", F: "HIJ",
G: true, H: true, I: true,
}
}
//go:noinline
func CreatePointer() *BigStruct {
return &BigStruct{
A: 123, B: 456, C: 789,
D: "ABC", E: "DEF", F: "HIJ",
G: true, H: true, I: true,
}
}
我们可以用目前使用的技术来验证上面的解释。1
2
3
4
5
6$ go build -gcflags '-m -l'
./main.go:67:9: &BigStruct literal escapes to heap
$ go test -bench . -benchmem
BenchmarkCopyIt-8 211907048 5.20 ns/op 0 B/op 0 allocs/op
BenchmarkPointerIt-8 20393278 52.6 ns/op 80 B/op 1 allocs/op
以下是我们将用于跟踪工具的测试。它们分别用各自的 Create 函数创建 20,000,000 个 BigStruct 实例。1
2
3
4
5
6
7
8
9
10
11
12
13const creations = 20_000_000
func TestCopyIt(t *testing.T) {
for i := 0; i < creations; i++ {
_ = CreateCopy()
}
}
func TestPointerIt(t *testing.T) {
for i := 0; i < creations; i++ {
_ = CreatePointer()
}
}
接下来,我们将把 CreateCopy 的跟踪输出保存到文件 copy_trace.out 中。并在浏览器中用跟踪工具打开它。1
2
3
4
5
6
7
8$ go test -run TestCopyIt -trace=copy_trace.out
PASS
ok github.com/Jimeux/go-samples/allocations 0.281s
$ go tool trace copy_trace.out
Parsing trace...
Splitting trace...
Opening browser. Trace viewer is listening on http://127.0.0.1:57530
从菜单中选择 View trace,我们看到了下面的画面,它几乎和我们的 stackIt 功能的火焰图一样不引人注目。8 个潜在的逻辑核(Procs)中只有 2 个被使用,goroutine G19 几乎花费整个时间运行我们的测试循环–这正是我们想要的。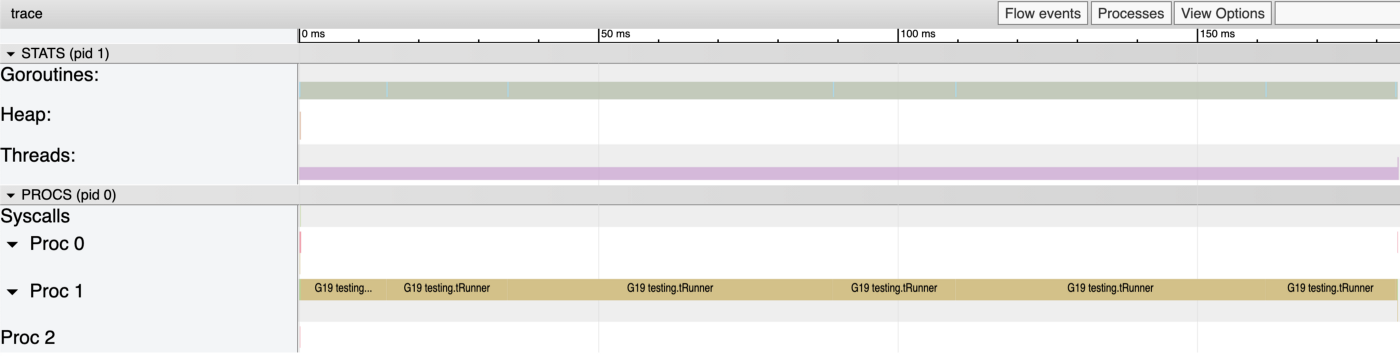
让我们为 CreatePointer 代码生成跟踪数据。1
2
3
4
5
6
7
8$ go test -run TestPointerIt -trace=pointer_trace.out
PASS
ok github.com/Jimeux/go-samples/allocations 2.224s
go tool trace pointer_trace.out
Parsing trace...
Splitting trace...
Opening browser. Trace viewer is listening on http://127.0.0.1:57784
您可能已经注意到,与 CreateCopy 的 0.281 秒相比,测试花费了 2.224 秒,选择 View trace 这次显示的内容更加丰富多彩,更加繁忙。所有的逻辑内核都被利用了,堆操作、线程和 goroutines 似乎比上次多了很多。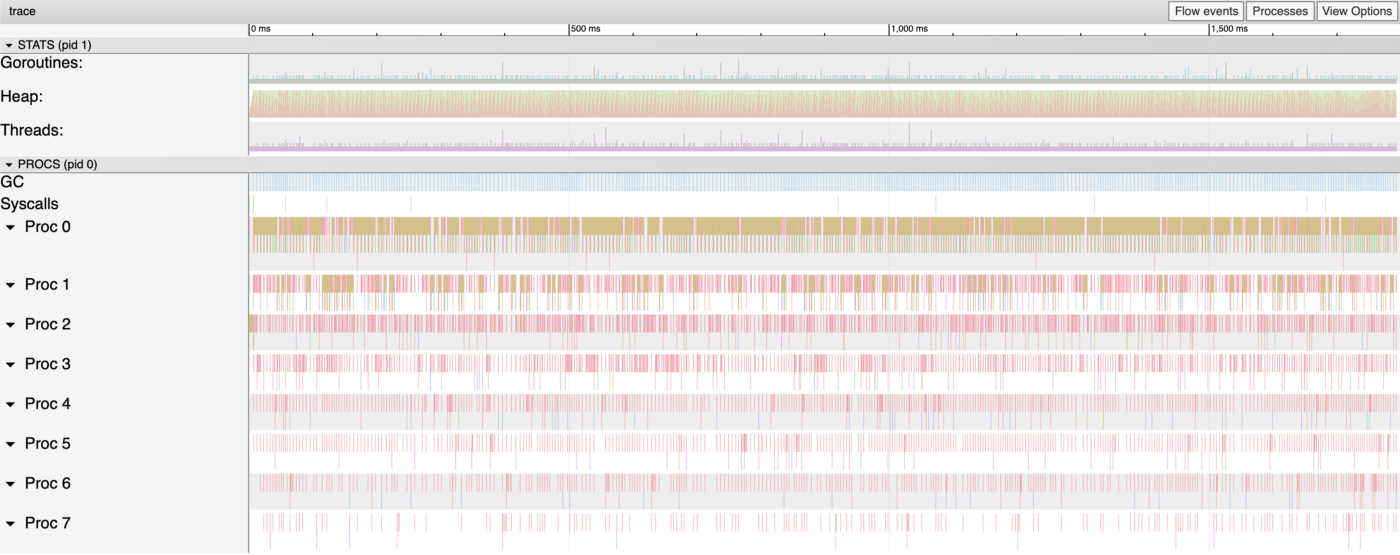
如果我们把跟踪的时间放大到一毫秒左右的跨度,我们会看到很多 goroutine 在执行与垃圾回收相关的操作。前面引用的 FAQ 中使用了“垃圾回收堆”这个词,因为垃圾回收器的工作就是清理堆上任何不再被引用的东西。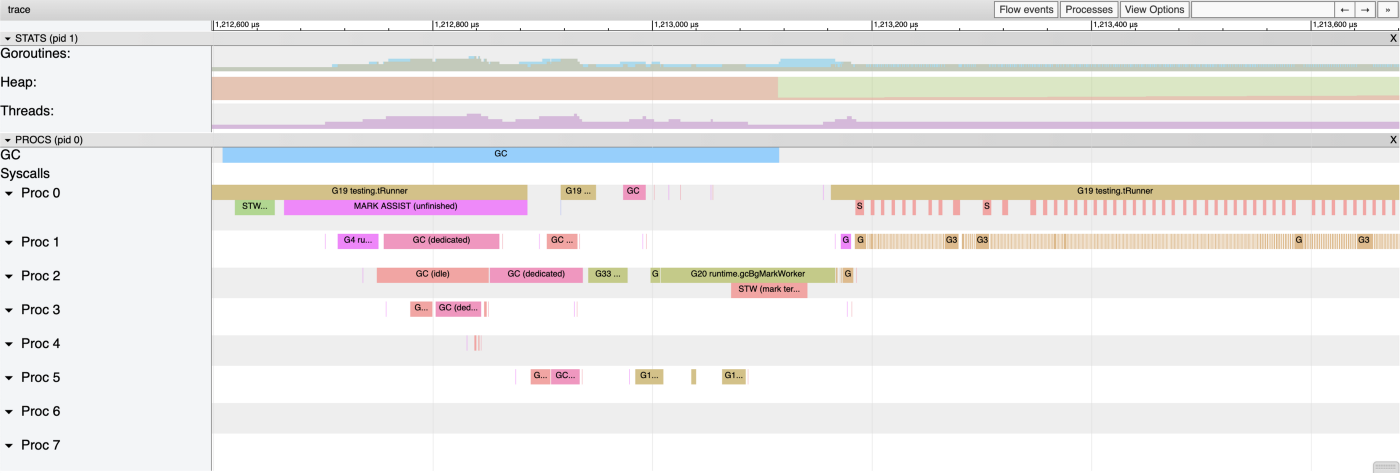
尽管 Go 的垃圾回收器效率越来越高,但这个过程并不是免费的。我们可以从上面的跟踪输出中直观地验证,测试代码有时完全停止了。对于 CreateCopy 来说,情况并非如此,因为我们所有的 BigStruct 实例仍然在栈上,GC 几乎没有什么事情可做。
比较两组跟踪数据中的 goroutine 分析可以更深入地了解这一点。CreatePointer(底部)花费了超过 15% 的执行时间来清扫或暂停(GC)和调度 goroutines。
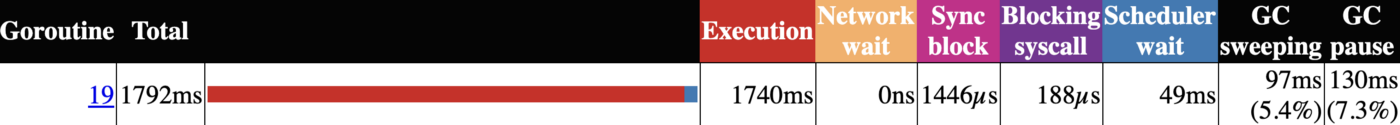
看看跟踪数据中其他地方的一些统计数据,可以进一步说明堆分配的成本,生成的 goroutine数量有明显的差异,CreatePointer 测试有近 400 个 STW(停止世界)事件。1
2
3
4
5
6
7
8
9+------------+------+---------+
| | Copy | Pointer |
+------------+------+---------+
| Goroutines | 41 | 406965 |
| Heap | 10 | 197549 |
| Threads | 15 | 12943 |
| bgsweep | 0 | 193094 |
| STW | 0 | 397 |
+------------+------+---------+
但请记住,尽管本节的标题是这样的,但 CreateCopy 测试的条件在一个典型的程序中是非常不现实的。GC 使用一致数量的 CPU 是很正常的,指针是任何真实程序的一个特征。然而,这和前面的火焰图一起给了我们一些启示,为什么我们可能要跟踪 allocs/op 统计,并尽可能避免不必要的堆分配。
总结
希望这篇文章能让大家了解到 Go 程序中栈和堆之间的区别、allocs/op 统计的意义,以及我们可以调研内存使用情况的一些方法。
代码的正确性和可维护性通常比减少指针使用和规避 GC 活动的技巧更重要。到目前为止,每个人都知道关于过早优化的那条线,在 Go 中编写代码也不例外。
然而,如果我们确实有严格的性能要求或在其他方面确定了程序中的瓶颈,这里介绍的概念和工具有望成为进行必要优化的有用起点。
如果你想玩玩这篇文章中的简单代码示例,请查看 GitHub 上的源代码和 README。

译自:https://medium.com/eureka-engineering/understanding-allocations-in-go-stack-heap-memory-9a2631b5035d