背景
在运行一段时间的go程序后内存竟然达到4G左右,几乎可以肯定是由于某段方法操作不规范引起的问题,于是对go程序进行分析
分析
分析内存光靠手撕代码是比较困难的,总要借助一些工具。Golang pprof是Go官方的profiling工具,非常强大,使用起来也很方便。
代码改造:1
2
3
4import _ "net/http/pprof"
go func() {
http.ListenAndServe("0.0.0.0:8888", nil)
}()
改造后程序启动后,浏览器中输入http://ip:8899/debug/pprof/就可以看到一个汇总分析页面,显示如下信息:1
2
3
4
5
6
7
8
9
10/debug/pprof/
profiles:
0 block
32 goroutine
552 heap
0 mutex
51 threadcreate
full goroutine stack dump
点击heap,在汇总分析页面的最上方可以看到如下图所示,红色箭头所指的就是当前已经使用的堆内存是25M!!
接下来我们需要借助go tool pprof来分析:1
go tool pprof -inuse_space http://本机Ip:8888/debug/pprof/heap
这个命令进入后,是一个类似gdb的交互式界面,输入 top 命令可以前10大的内存分配,flat 是堆栈中当前层的inuse内存值,cum是堆栈中本层级的累计inuse内存值(包括调用的函数的inuse内存值,上面的层级)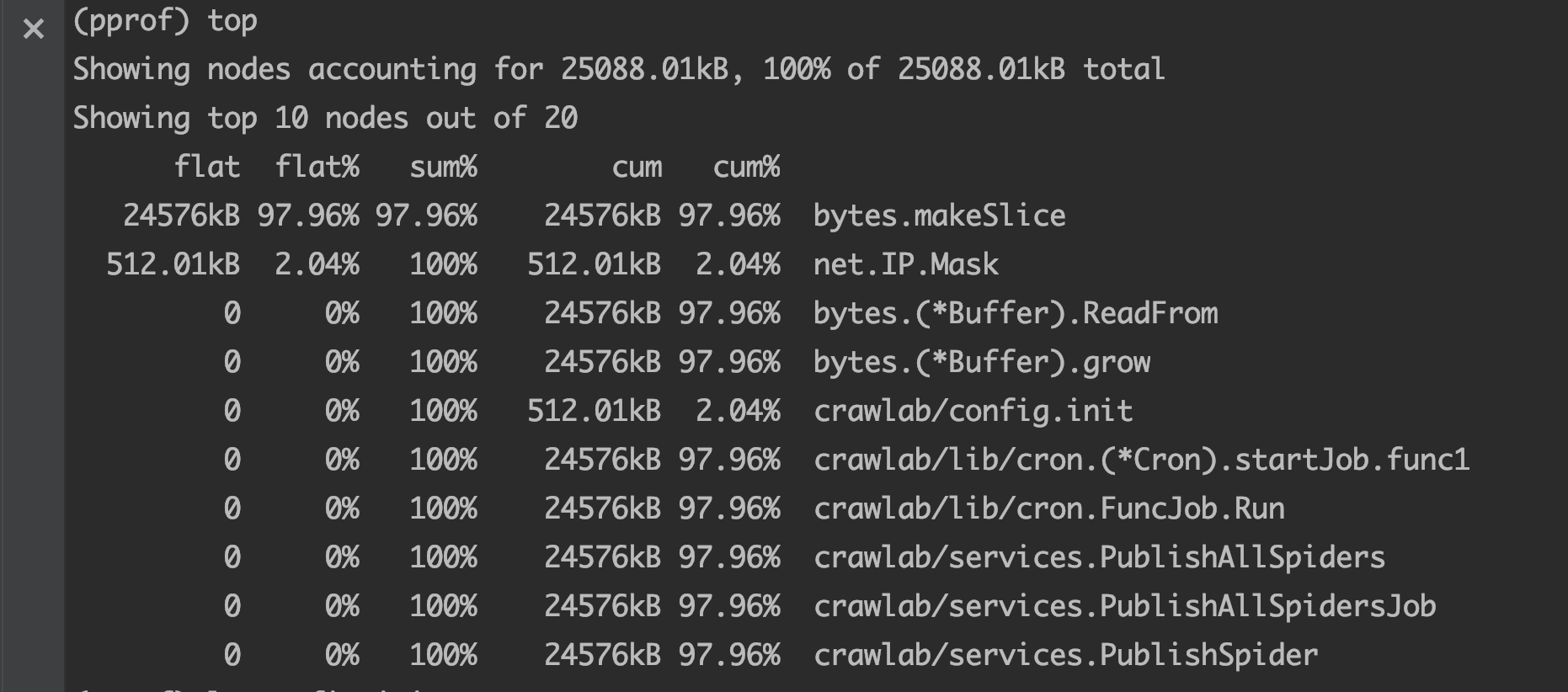
可以看到,bytes.makeSlice这个内置方法竟然使用了24M内存,继续往下看,可以看到ReadFrom这个方法,搜了一下,发现 ioutil.ReadAll() 里会调用 bytes.Buffer.ReadFrom, 而 bytes.Buffer.ReadFrom 会进行 makeSlice。再回头看一下io/ioutil.readAll的代码实现,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21func readAll(r io.Reader, capacity int64) (b []byte, err error) {
buf := bytes.NewBuffer(make([]byte, 0, capacity))
defer func() {
e := recover()
if e == nil {
return
}
if panicErr, ok := e.(error); ok && panicErr == bytes.ErrTooLarge {
err = panicErr
} else {
panic(e)
}
}()
_, err = buf.ReadFrom(r)
return buf.Bytes(), err
}
// bytes.MinRead = 512
func ReadAll(r io.Reader) ([]byte, error) {
return readAll(r, bytes.MinRead)
}
可以看到,ioutil.ReadAll 每次都会分配初始化一个大小为 bytes.MinRead 的 buffer ,bytes.MinRead 在 Golang 里是一个常量,值为 512 。就是说每次调用 ioutil.ReadAll 都会分配一块大小为 512 字节的内存,目前看起来是正常的,但我们再看一下ReadFrom的实现,1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35// ReadFrom reads data from r until EOF and appends it to the buffer, growing
// the buffer as needed. The return value n is the number of bytes read. Any
// error except io.EOF encountered during the read is also returned. If the
// buffer becomes too large, ReadFrom will panic with ErrTooLarge.
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
b.lastRead = opInvalid
// If buffer is empty, reset to recover space.
if b.off >= len(b.buf) {
b.Truncate(0)
}
for {
if free := cap(b.buf) - len(b.buf); free < MinRead {
// not enough space at end
newBuf := b.buf
if b.off+free < MinRead {
// not enough space using beginning of buffer;
// double buffer capacity
newBuf = makeSlice(2*cap(b.buf) + MinRead)
}
copy(newBuf, b.buf[b.off:])
b.buf = newBuf[:len(b.buf)-b.off]
b.off = 0
}
m, e := r.Read(b.buf[len(b.buf):cap(b.buf)])
b.buf = b.buf[0 : len(b.buf)+m]
n += int64(m)
if e == io.EOF {
break
}
if e != nil {
return n, e
}
}
return n, nil // err is EOF, so return nil explicitly
}
这个函数主要作用就是从 io.Reader 里读取的数据放入 buffer 中,如果 buffer 空间不够,就按照每次 2x + MinRead 的算法递增,这里 MinRead 的大小也是 512 Bytes ,也就是说如果我们一次性读取的文件过大,就会导致所使用的内存倍增,假设我们的爬虫文件总共有500M,那么所用的内存就有500M * 2 + 512B,况且爬虫文件中还带了那么多log文件,那看看crawlab源码中是哪一段使用ioutil.ReadAll读了爬虫文件,定位到了这里:
这里直接将全部的文件内容,以二进制的形式读了进来,导致内存倍增,令人窒息的操作。
解决方法
其实在读大文件的时候,把文件内容全部读到内存,直接就翻车了,正确是处理方法有两种
流式处理
1 | func ReadFile(filePath string, handle func(string)) error { |
分片处理
当读取的是二进制文件,没有换行符的时候,使用这种方案比较合适
1 | func ReadBigFile(fileName string, handle func([]byte)) error { |
参考:
- juejin.im/post/5d5be347f265da03b94ff66b