概述
文章介绍了 K8s 的一些核心网络模型和设计、Cilium 对 K8s Service 的实现、BPF/XDP 性能优化,以及他们从中得到的一些实践经验,全是干货。
去年我们也参加了这个大会(LPC),并做了题为 Making the Kubernetes Service Abstraction Scale using eBPF 的分享。 今天的内容是去年内容的延续,具体分为三个部分:
- Kubernetes 网络模型
Cilium对K8s Service负载均衡的实现,以及我们的一些实践经验- 一些新的
BPF内核扩展
1 K8s 网络基础:访问集群内服务的几种方式
Kubernetes 是一个分布式容器调度器,最小调度单位是 Pod。从网络的角度来说,可以认为 一个 pod 就是网络命名空间的一个实例(an instance of network namespace)。 一个 pod 内可能会有多个容器,因此,多个容器可以共存于同一个网络命名空间。
需要注意的是:K8s 只定义了网络模型,具体实现则是交给所谓的 CNI 插件,后者完成 pod 网络的创建和销毁。本文接下来将以 Cilium CNI 插件作为例子。
K8s 规定了每个 pod 的 IP 在集群内要能访问,这是通过 CNI 来完成的:CNI 插件负责为 pod 分配 IP 地址,然后为其创建和打通网络。 除此之外,K8s 没有对 CNI 插件做任何限制。尤其是,K8s 没有对从集群外访问 pod 的行为做任何规定。
接下来我们就来看看如何访问 K8s 集群里的一个服务(通常会对应多个 backend pods)。
1.1 PodIP(直连容器 IP)
第一种方式是通过 PodIP 直接访问,这是最简单的方式。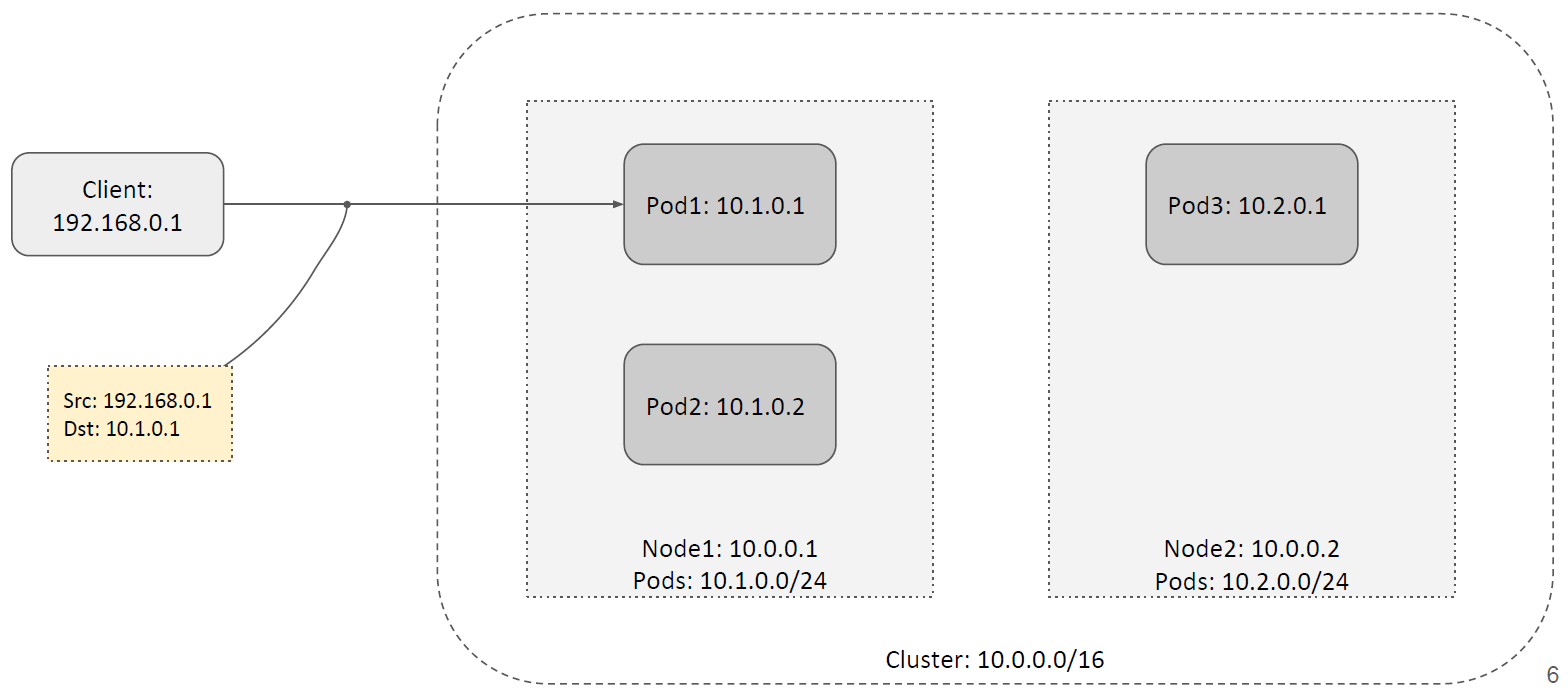
如上图所示,这个服务的 3 个 backend pods 分别位于两个 node 上。当集群外的客户端 访问这个服务时,它会直接通过某个具体的 PodIP 来访问。
假设客户端和 Pod 之间的网络是可达的,那这种访问是没问题的。
但这种方式有几个缺点:
- pod 会因为某些原因重建,而 K8s 无法保证它每次都会分到同一个 IP 地址。例如,如果 node 重启了,pod 很可能就会分到不同的 IP 地址,这对客户端来说个 大麻烦。
- 没有内置的负载均衡。即,客户端选择一个 PodIP 后,所有的请求都会发送到这个 pod,而不是分散到不同的后端 pod。
1.2 HostPort(宿主机端口映射)
第二种方式是使用所谓的 HostPort。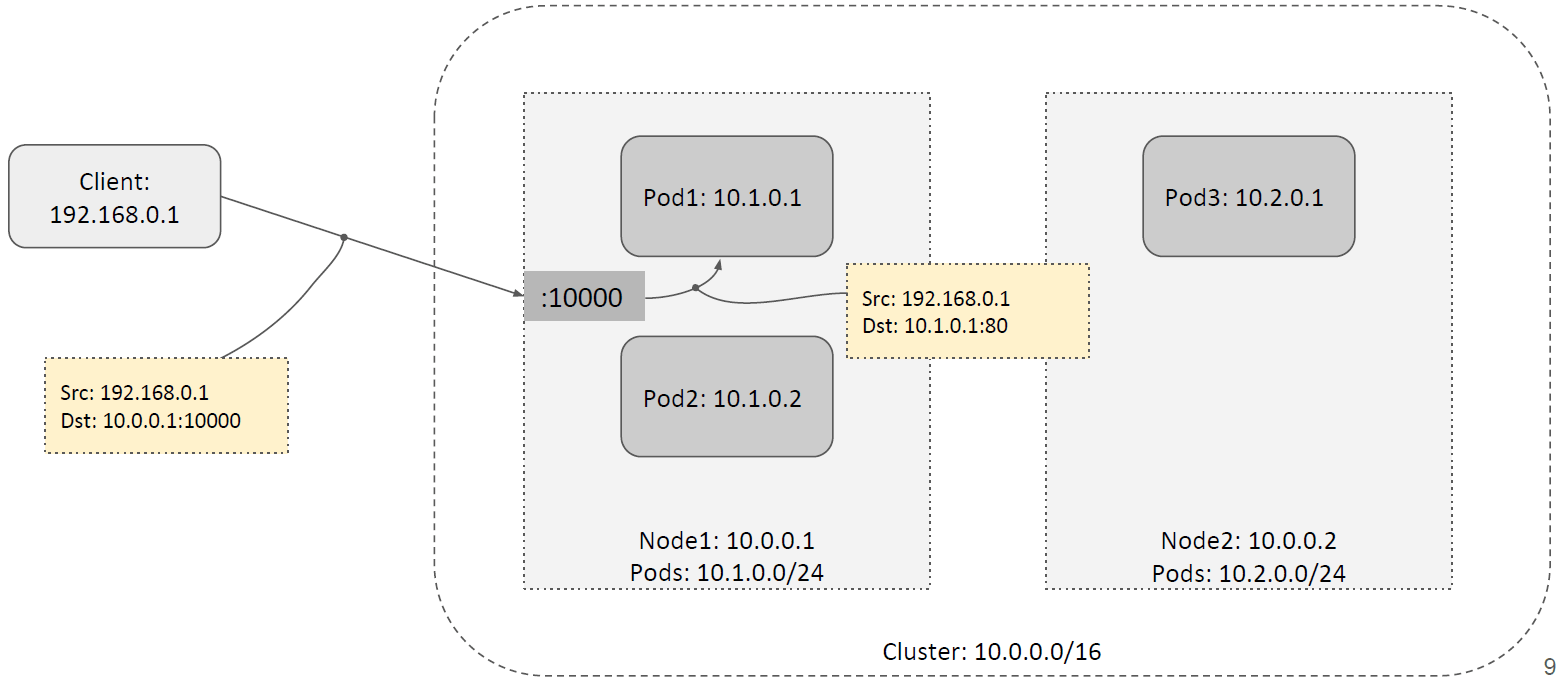
如上图所示,在宿主机的 netns 分配一个端口,并将这个端口的所有流量转发到 后端 pod。
这种情况下,
- 客户端通过 Pod 所在的宿主机的
HostIP:HostPort访问服务,例如上图中访问10.0.0.1:10000; - 宿主机先对流量进行 DNAT,然后转发给 Pod。
这种方式的缺点:
- 宿主机的端口资源是所有 Pod 共享的,任何一个端口只能被一个 pod 使用 ,因此在每台 node 上,任何一个服务最多只能有一个 pod(每个 backend 都是一 致的,因此需要使用相同的 HostPort)。对用户非常不友好。
- 和 PodIP 方式一样,没有内置的负载均衡。
1.3 NodePort Service
NodePort 和上面的 HostPort 有点像(可以认为是 HostPort 的增强版),也是将 Pod 暴 露到宿主机 netns 的某个端口,但此时,集群内的每个 Node 上都会为这个服务的 pods 预留这个端口,并且将流量负载均衡到这些 pods。
如下图所示,假设这里的 NodePort 是 30001。当客户端请求到达任意一台 node 的 30001 端口时,它可以对请求做 DNAT 然后转发给本节点内的 Pod,如下图所示: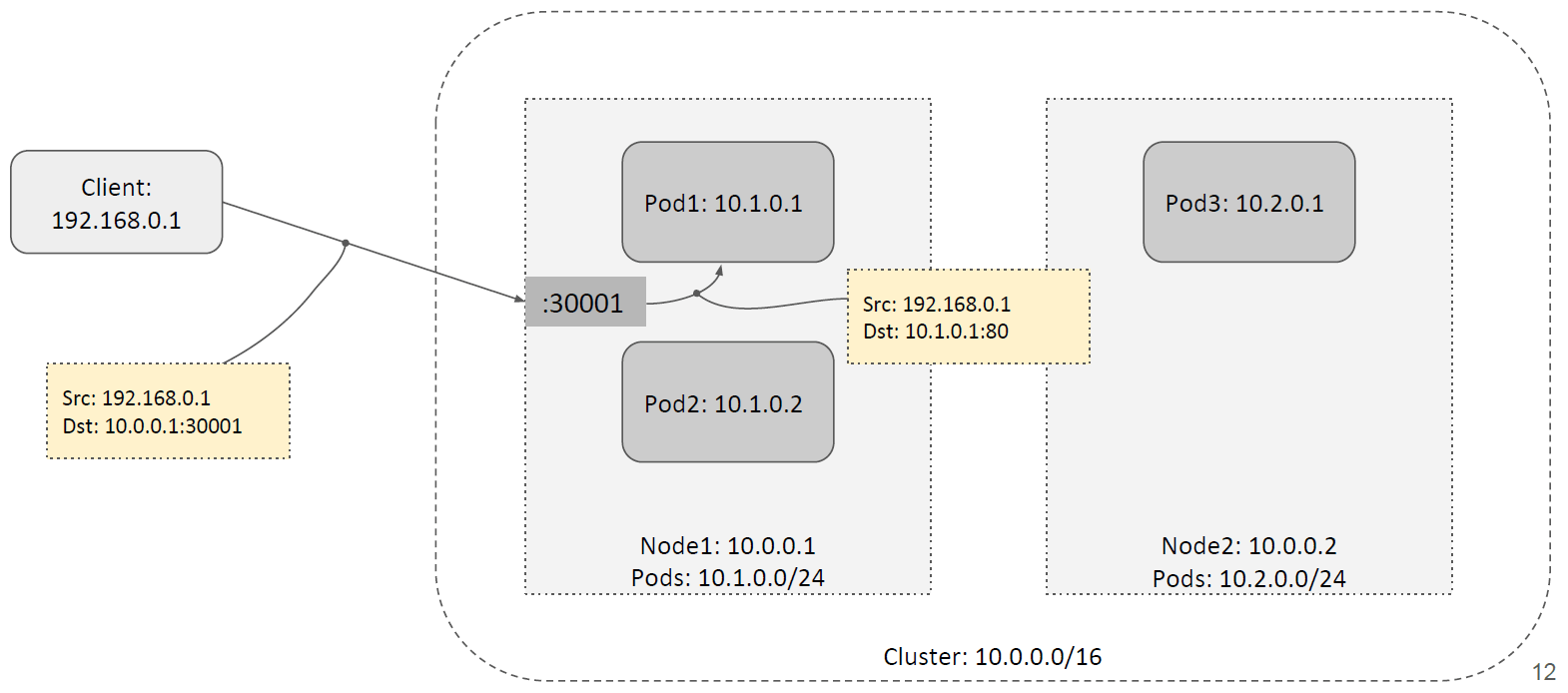
也可以 DNAT 之后将请求转发给其他节点上的 pod,如下图所示: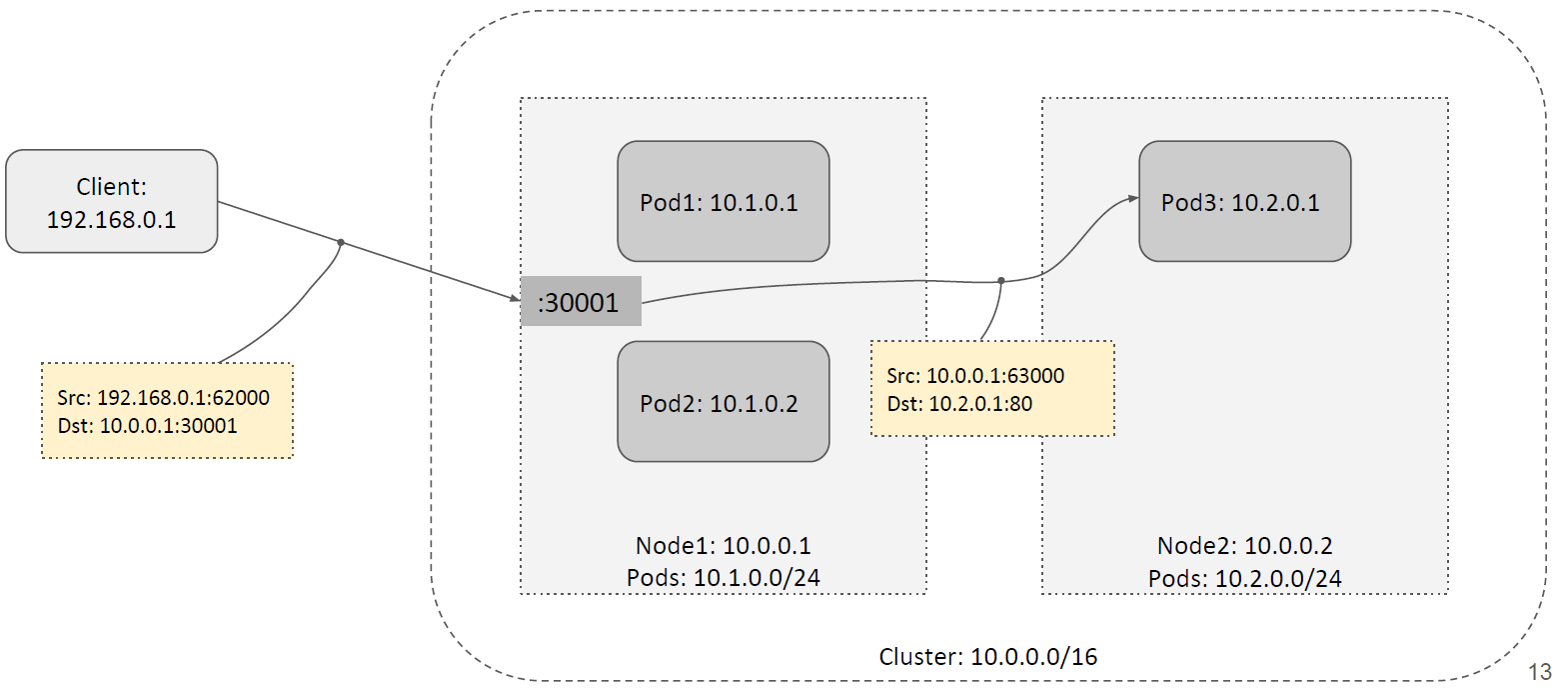
注意在后面跨宿主机转发的情况下,除了做 DNAT 还需要做 SNAT。
优点:
- 已经有了服务(service)的概念,多个 pod 属于同一个 service,挂掉一个时其 他 pod 还能继续提供服务。
- 客户端不用关心 pod 在哪个 node 上,因为集群内的所有 node 上都开了这个端 口并监听在那里,它们对全局的 backend 有一致的视图。
- 已经有了负载均衡,每个 node 都是 LB。
- 在宿主机 netns 内访问这些服务时,通过
localhost:NodePort就行了,无需 DNS 解析。
缺点:
- 大部分实现都是基于 SNAT,当 pod 不在本节点时,导致 packet 中的真实客户端 IP 地址信息丢失,监控、排障等不方便。
- Node 做转发使得转发路径多了一跳,延时变大。
1.4 ExternalIPs Service
第四种从集群外访问 service 的方式是 external IP。
如果有外部可达的 IP ,即集群外能通过这个 IP 访问到集群内特定的 nodes,那我 们就可以通过这些 nodes 将流量转发到 service 的后端 pods,并提供负载均衡。
如下图所示,1.1.1.1 是一个 external IP,所有目的 IP 地址是 1.1.1.1 的流量会被底层的网络(K8s 控制之外)转发到 node1。1.1.1.1:8080 在 K8s 里定义了一个 Service,如果它将流量转发到本机内的 backend pod,需要做一次 DNAT: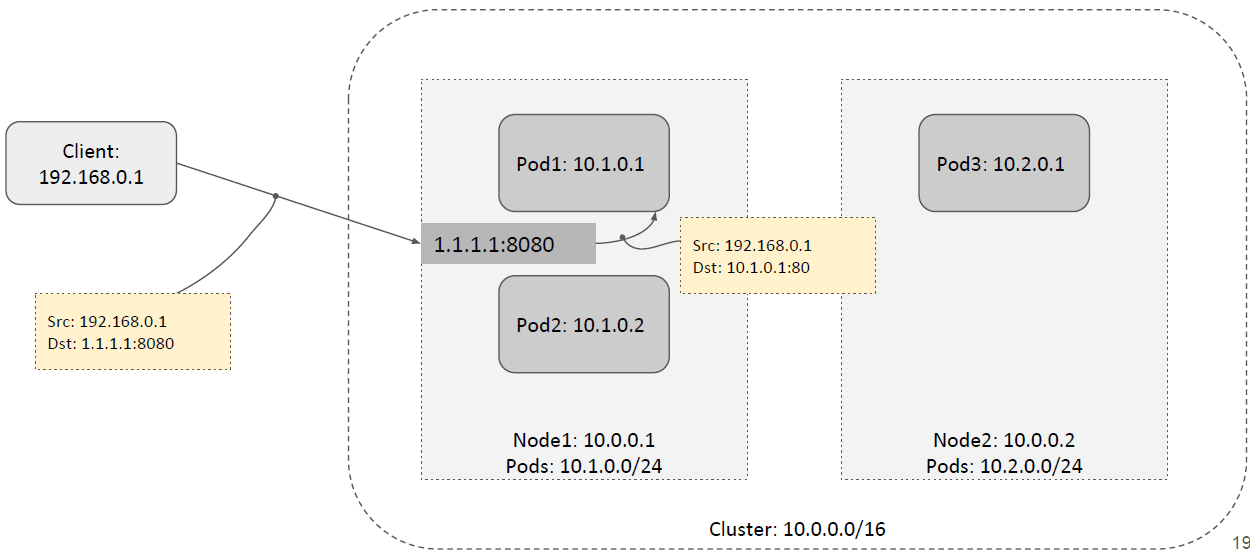
同样,这里的后端 Pod 也可以在其他 node 上,这时除了做 DNAT 还需要做一次 SNAT, 如下图所示: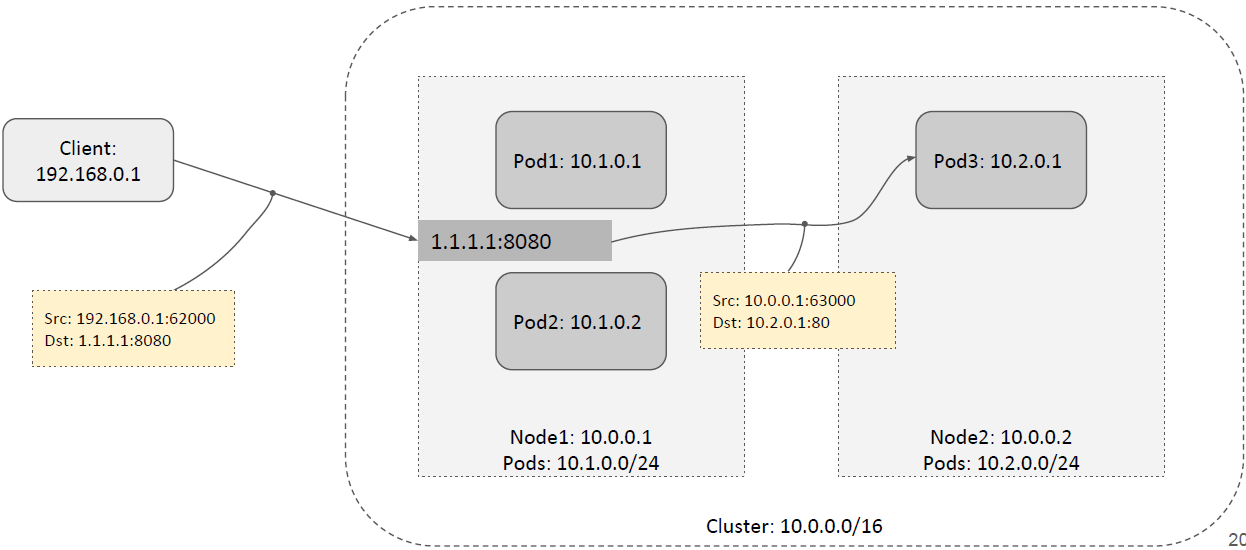
优点:可以使用任何外部可达的 IP 地址来定义 Service 入口,只要用这个 IP 地址能访问集群内的至少一台机器即可。
缺点:
- External IP 在 k8s 的控制范围之外,是由底层的网络平台提供的。例如,底层网 络通过 BGP 宣告,使得 IP 能到达某些 nodes。
- 由于这个 IP 是在 k8s 的控制之外,对 k8s 来说就是黑盒,因此从集群内访问 external IP 是存在安全隐患的,例如
external IP上可能运行了 恶意服务,能够进行中间人攻击。因此,Cilium目前不支持在集群内通过external IP访问 Service。
1.5 LoadBalancer Service
第五种访问方式是所谓的 LoadBalancer 模式。针对公有云还是私有云,LoadBalancer 又分为两种。
1.5.1 私有云
如果是私有云,可以考虑实现一个自己的 cloud provider,或者直接使用 MetalLB。
如下图所示,这种模式和 externalIPs 模式非常相似,local 转发: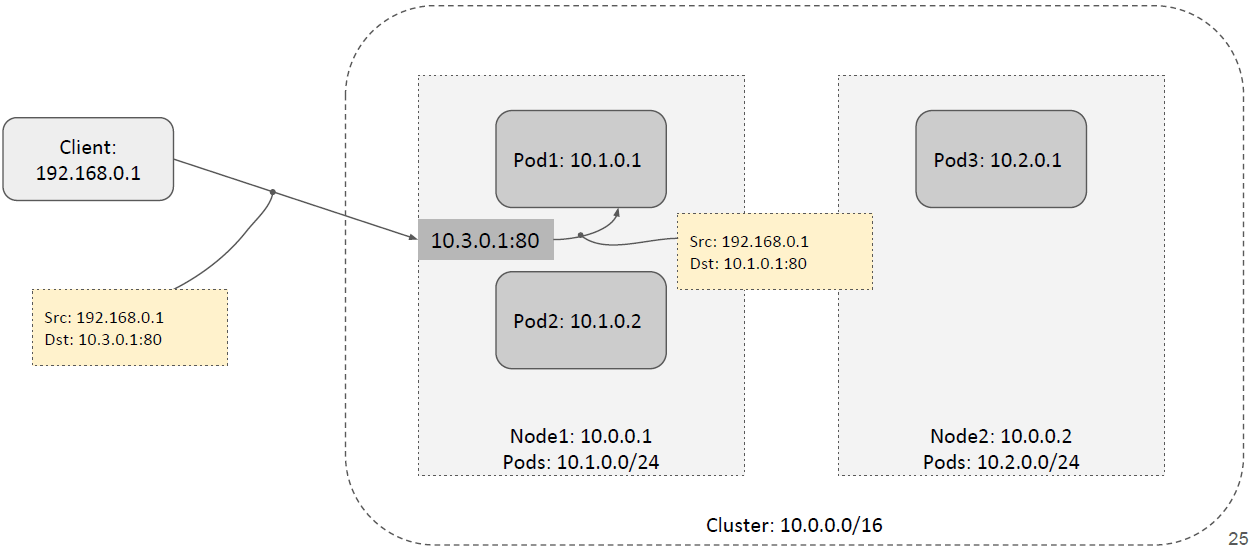
remote 转发: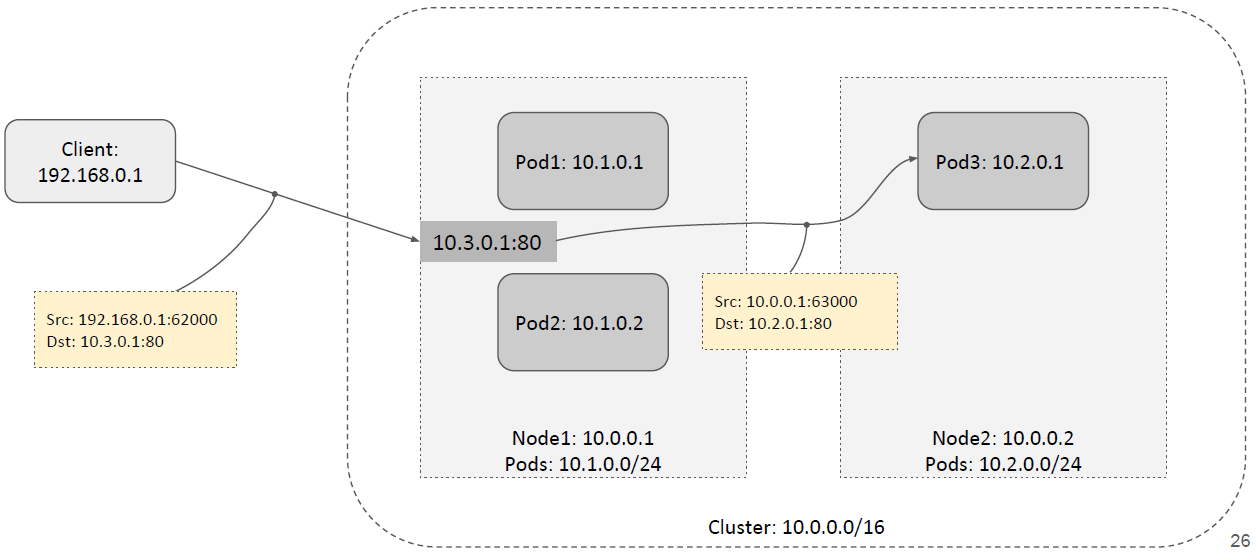
但是,二者有重要区别:
- externalIPs 在 K8s 的控制之外,使用方式是从某个地方申请一个 external IP, 然后填到 Service 的 Spec 里;这个
external IP是存在安全隐患的,因为并不是 K8s 分配和控制的; - LoadBalancer 在 K8s 的控制之内,只需要声明 这是一个 LoadBalancer 类型的 Service,K8s 的
cloud-provider组件就会自动给这个 Service 分配一个外部可达的 IP,本质上cloud-provider做的事情就是从某个 LB 分配一个受信任的 VIP 然后填到 Service 的 Spec 里。
优点:LoadBalancer 分配的 IP 是归 K8s 管的,用户无法直接配置这些 IP,因 此也就避免了前面 external IP 的流量欺骗(traffic spoofing)风险。
但注意这些 IP 不是由 CNI 分配的,而是由 LoadBalancer 实现分配。
MetalLB 能完成 LoadBalancer IP 的分配,然后基于 ARP/NDP 或 BGP 宣告 IP 的可达性。 此外,MetalLB 本身并不在 critical fast path 上(可以认为它只是控制平面,完成 LoadBalancer IP 的生效,接下来的请求和响应流量,即数据平面,都不经过它),因此不 影响 XDP 的使用。
1.5.2 公有云
主流的云厂商都实现了 LoadBalancer,在它们提供的托管 K8s 内可以直接使用。
特点:
- 有专门的 LB 节点作为统一入口。
- LB 节点再将流量转发到 NodePort。
- NodePort 再将流量转发到 backend pods。
如下图所示,local 转发: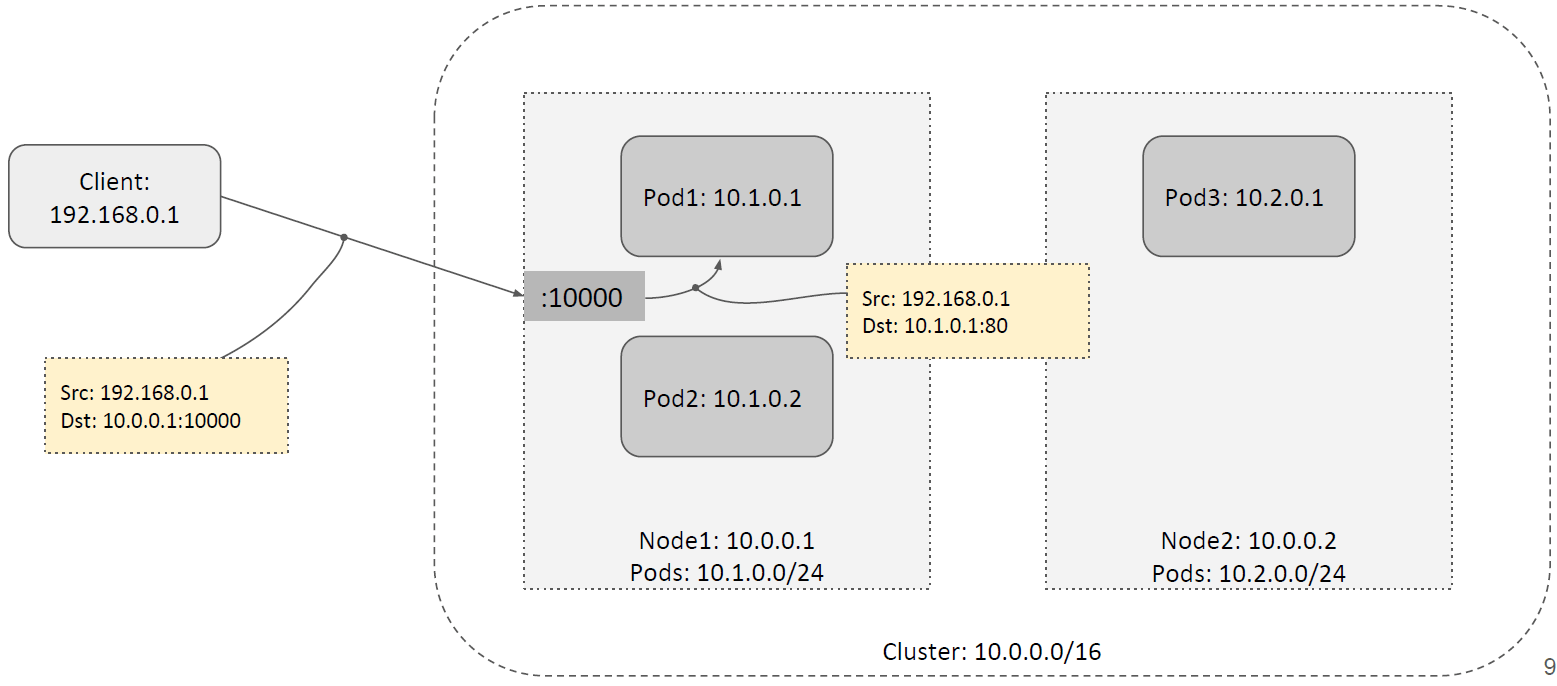
remote 转发: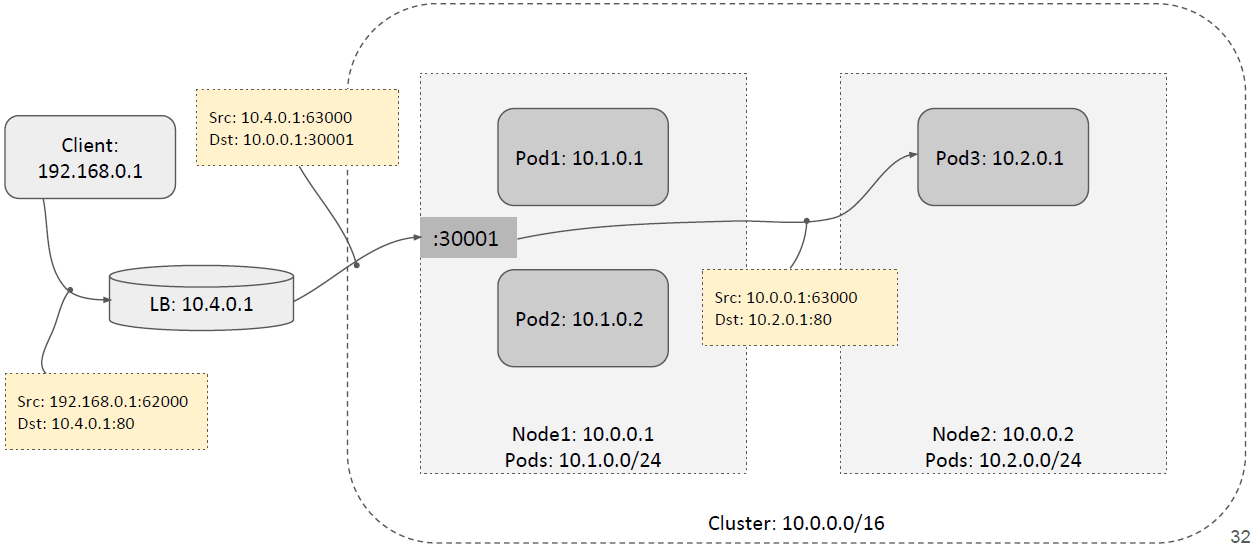
优点:
- LoadBalancer 由云厂商实现,无需用户安装 BGP 软件、配置 BGP 协议等来宣告 VIP 可达性。
- 开箱即用,主流云厂商都针对它们的托管 K8s 集群实现了这样的功能。
在这种情况下,Cloud LB 负责检测后端 node(注意不是后端 pod)的健康状态。
缺点:
- 存在两层 LB:LB 节点转发和 node 转发。
- 使用方式因厂商而已,例如各厂商的 annotations 并没有标准化到 K8s 中,跨云使用会有一些麻烦。
- Cloud API 非常慢,调用厂商的 API 来做拉入拉出非常受影响。
1.6 ClusterIP Service
最后一种是集群内访问 Service 的方式:ClusterIP 方式。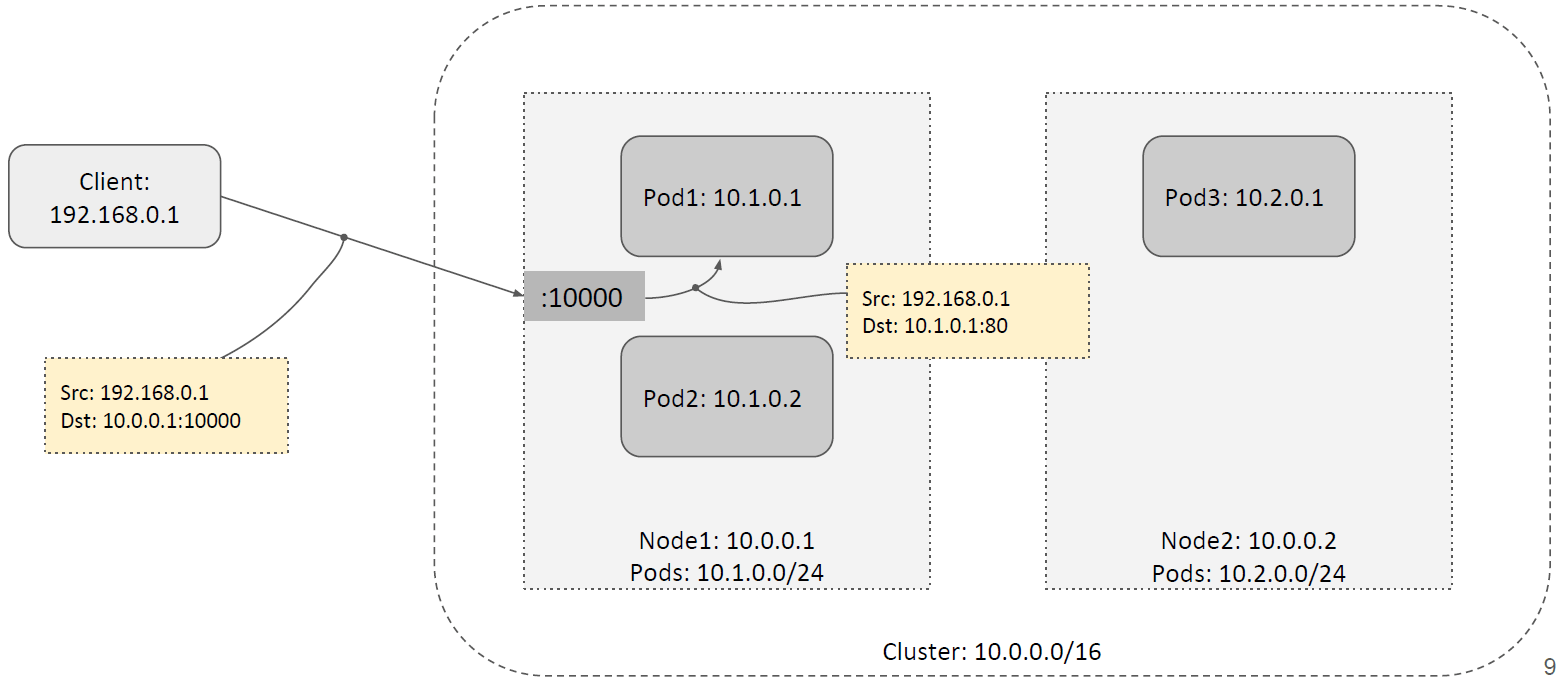
ClusterIP 也是 Service 的一种 VIP,但这种方式只适用于从集群内访问 Service,例如 从一个 Pod 访问相同集群内的一个 Service。
ClusterIP 的特点:
- ClusterIP 使用的 IP 地址段是在创建 K8s 集群之前就预留好的;
- ClusterIP 不可路由(会在出宿主机之前被拦截,然后 DNAT 成具体的 PodIP);
- 只能在集群内访问(For in-cluster access only)。
实际上,当创建一个 LoadBalancer 类型的 Service 时,K8s 会为我们自动创建三种类 型的 Service:
- LoadBalancer
- NodePort
- ClusterIP
这三种类型的 Service 对应着同一组 backend pods。
我们此次分享的第一部分,K8s 网络基础至此就要结束了,实际上还有很多与 Service 相 关的 K8s 特性,例如 sessionAffinity 和 externalTrafficPolicy,但这里就不展开了,有兴趣可以参考附录。
2 K8s Service 负载均衡:Cilium 基于 BPF/XDP 的实现
Cilium 基于 eBPF/XDP 实现了前面提到的所有类型的 K8s Service。实现方式是:
- 在每个 node 上运行一个
cilium-agent; cilium-agent监听K8s apiserver,因此能够感知到 K8s 里 Service 的变化;- 根据 Service 的变化动态更新 BPF 配置。
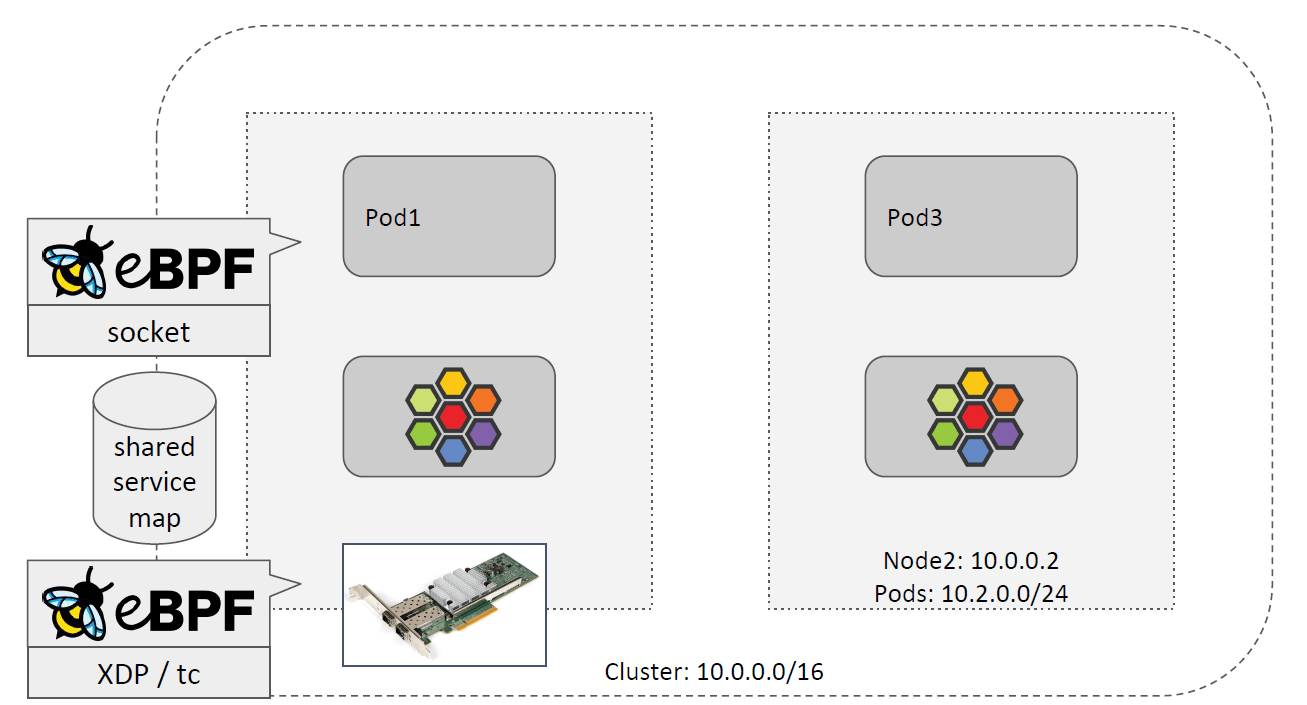
如上图所示,Service 的实现由两个主要部分组成:
- 运行在 socket 层的 BPF 程序
- 运行在 tc/XDP 层的 BPF 程序
以上两者共享 service map 等资源,其中存储了 service 及其 backend pods 的映射关系。
2.1 Socket 层负载均衡(东西向流量)
Socket 层 BPF 负载均衡负责处理集群内的东西向流量。
实现
实现方式是:将 BPF 程序 attach 到 socket 的系统调用 hooks,使客户端直接和后端 pod 建连和通信,如下图所示,这里能 hook 的系统调用包括 connect()、sendmsg()、 recvmsg()、getpeername()、bind() 等,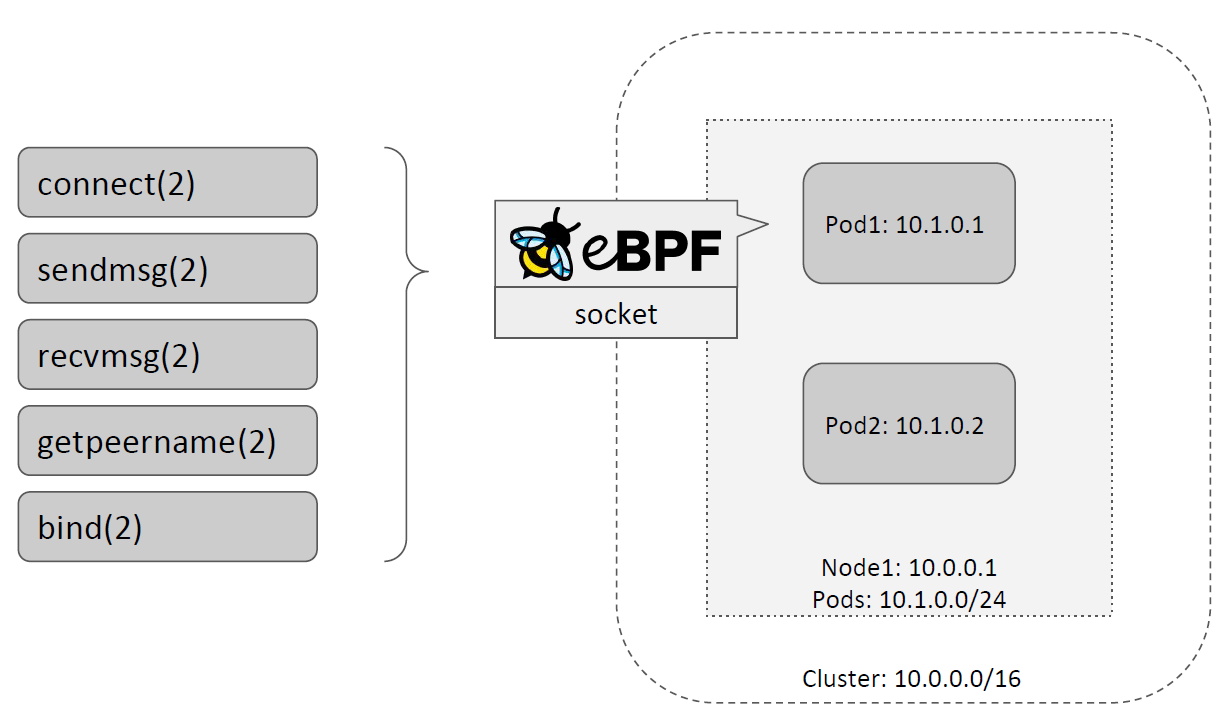
这里的一个问题是,K8s 使用的还是 cgroup v1,但这个功能需要使用 v2,而由于 兼容性问题,v2 完全替换 v1 还需要很长时间。所以我们目前所能做的就是 支持 v1 和 v2 的混合模式。这也是为什么 Cilium 会 mount 自己的 cgroup v2 instance 的原因。
Cilium mounts cgroup v2, attaches BPF to root cgroup. Hybrid use works well for root v2.
具体到实现上,
connect + sendmsg做正向变换(translation)recvmsg + getpeername做反向变换,
这个变换或转换是基于 socket structure 的,此时还没有创建 packet,因此不存在 packet 级别的 NAT!目前已经支持 TCP/UDP v4/v6, v4-in-v6。应用对此是无感知的,它以为自己连接到的还是 Service IP,但其实是 PodIP。
查找后端 pods
Service lookup 不一定能选到所有的 backend pods(scoped lookup),我们将 backend pods 拆成不同的集合。
这样设计的好处:可以根据流量类型,例如是来自集群内还是集群外( internal/external),来选择不同的 backends。例如,如果是到达 node 的 external traffic,我们可以限制它只能选择本机上的 backend pods,这样相比于转发到其他 node 上的 backend 就少了一跳。
另外,还支持通配符(wildcard)匹配,这样就能将 Service 暴露到 localhost 或者 loopback 地址,能在宿主机 netns 访问 Service。但这种方式不会将 Service 暴露到宿 主机外面。
好处
显然,这种 socket 级别的转换是非常高效和实用的,它可以直接将客户端 pod 连 接到某个 backend pod,与 kube-proxy 这样的实现相比,转发路径少了好几跳。
此外,bind BPF 程序在 NodePort 冲突时会直接拒绝应用的请求,因此相比产生流 量(packet)然后在后面的协议栈中被拒绝,bind 这里要更加高效,因为此时 流量(packet)都还没有产生。
对这一功能至关重要的两个函数:
bpf_get_socket_cookie()
主要用于 UDP sockets,我们希望每个 UDP flow 都能选中相同的 backend pods。bpf_get_netns_cookie()
用在两个地方:- 用于区分
host netns和pod netns,例如检测到在host netns执行 bind 时,直接拒绝(reject); - 用于
serviceSessionAffinity,实现在某段时间内永远选择相同的 backend pods。
- 用于区分
由于 cgroup v2 不感知 netns,因此在这个 context 中我们没用 Pod 源 IP 信 息,通过这个 helper 能让它感知到源 IP,并以此作为它的 source identifier。
2.2 TC & XDP 层负载均衡(南北向流量)
第二种是进出集群的流量,称为南北向流量,在宿主机 tc 或 XDP hook 里处理。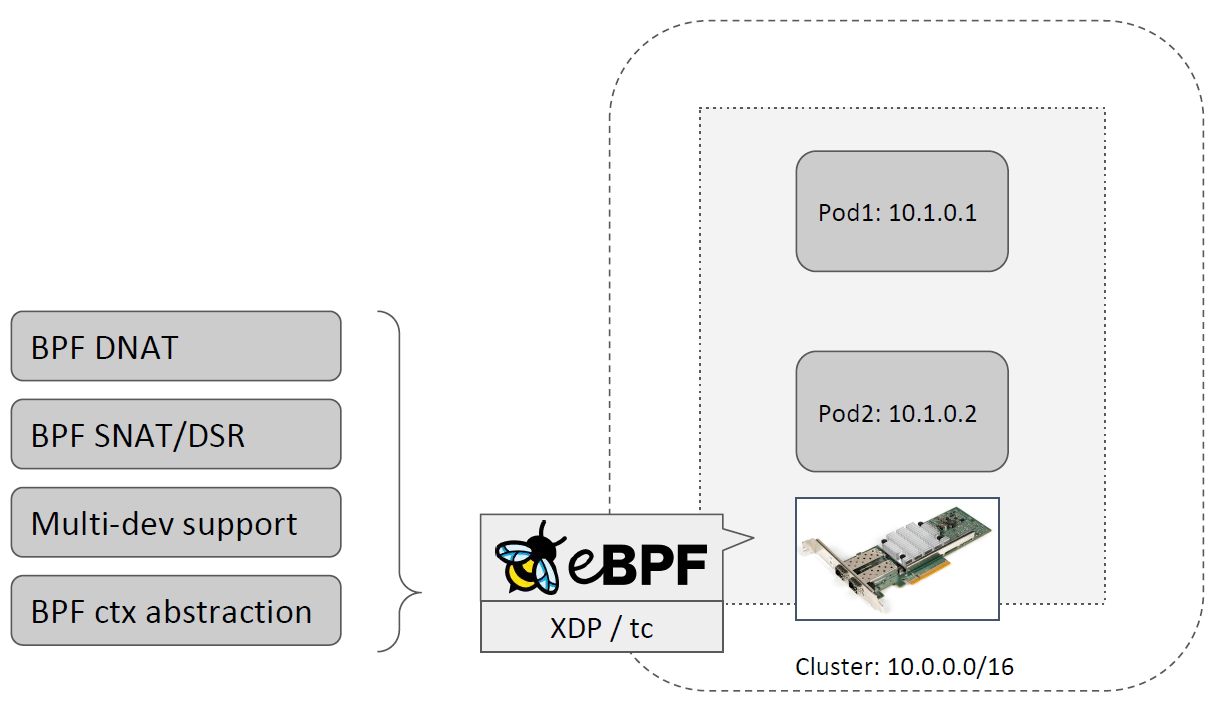
BPF 做的事情,将入向流量转发到后端 Pod,
- 如果 Pod 在本节点,做 DNAT;
- 如果在其他节点,还需要做 SNAT 或者 DSR。
这些都是 packet 级别的操作。
2.3 XDP 相关优化
在引入 XDP 支持时,为了使 context 的抽象更加通用,我们做了很多事情。下面就其中的 一些展开讨论。
BPF/XDP context 通用化
DNAT/SNAT engine, DSR, conntrack 等等都是在 tc BPF 里实现的。 BPF 代码中用 context 结构体传递数据包信息。
支持 XDP 时遇到的一个问题是:到底是将 context 抽象地更通用一些,还是直接实现一个 支持 XDP 的最小子集。我们最后是花大力气重构了以前几乎所有的 BPF 代码,来使得它更 加通用。好处是共用一套代码,这样对代码的优化同时适用于 TC 和 XDP 逻辑。
下面是一个具体例子:
ctx 是一个通用抽象,具体是什么类型和 include 的头文件有关,基于 cxt 可以同时处 理 tc BPF 和 XDP BPF 逻辑,
例如对于 XDP 场景,编译时这些宏会被相应的 XDP 实现替换掉:
内联汇编:绕过编译器自动优化
我们遇到的另一个问题是:tc BPF 中已经为 skb 实现了很多的 helper 函数,由于共用一 套抽象,因此现在需要为 XDP 实现对应的一套函数集。这些 helpers 都是 inline 函数, 而 LLVM 会对 inline 函数的自动优化会导致接下来校验器(BPF verifier)失败。
我们的解决方式是用 inline asm(内联汇编)来绕过这个问题。
下面是一个具体例子:xdp_load_bytes(),使用下面这段等价的汇编代码,才能让 verifier 认出来:
避免在用户侧使用 generic XDP
5.6 内核对 XDP 来说是一个里程碑式的版本(但可能不会是一个 LTS 版本),这个版本使得 XDP 在公有云上大规模可用了,例如 AWS ENA 和 Azure hv_netvsc 驱动。 但如果想跨平台使用 XDP,那你只应该使用最基本的一些 API,例如 XDP_PASS/DROP/TX 等等。
Cilium 在用户侧只使用 native XDP(only supports native XDP on user side), 我们也用 Generic XDP,但目前只限于 CI 等场景。
为什么我们避免在用户侧使用 generic XDP 呢?因为这套 LB 逻辑会运行在集群内的 每个 node 上,目前 linearize skb 以及 bypass GRO 会增加太大的 overhead。
自定义内存操作函数
现在回到加载和存储字节相关的辅助函数(load and store bytes helpers)。
查看 BPF 反汇编代码时,发现内置函数会执行字节级别(byte-wise)的一些操作,因此我们实现了自己优化过的 mem{cpy,zero,cmp,move}() 函数。这一点做起来还是比较容 易的,因为 LLVM 对栈外数据(non-stack data)没有上下文信息,例如 packet data 、map data,因而它无法准确地知道底层的架构是否支持高效的非对齐访问(unaligned access)。
另外,在基准测试中我们发现,大流量的场景下,bpf_ktime_get_ns() 在 XDP 中的开 销非常大,因此我们将 clock source 变成可选的,Cilium 启动时会执行检查,如果内 核支持,就自动切换到 bpf_jiffies64()(精度更低,但 conntrack 不需要那么高的 精度),这使得转发性能增加了大约 1.1Mpps。
cb (control buffer)
tc BPF 中大量使用 skb->cb[] 来传递数据,显然,XDP 中也是没有这个东西的。
为了在 XDP 中传递数据,我们最开始使用的是 xdp_adjust_meta(),但有两个缺点:
- missing driver support
- high rate of cache-misses
后来换成 per-CPU scratch map(每个 CPU 独立的、内容可随意修改的 map), 增加了大约 1.2Mpps。
bpf_map_update_elem()
在 fast path 中有很多 bpf_map_update_elem() 调用,触发了 bucket spinlock。
如果流量来自多个 CPU,这里可以优化的是:先检查一下是否需要更新(这一步不需要加锁 ),如果原来已经存在,并且需要更新的值并没有变,那就直接返回,
bpf_fib_lookup()
bpf_fib_lookup() 开销非常大,但在 XDP 中,例如 hairpin LB 场景,是不需要这个 函数的,可以在编译时去掉。我们在测试环境的结果显示可以提高 1.5Mpps。
静态 key
作为这次分享的最后一个例子,不要对不确定的 LLVM 行为做任何假设。
我们在 BPF map 的基础上有大量的尾调用,它们有静态的 keys,能够在编译期间确 定 key 的大小。我们还实现了一个内联汇编来做静态的尾递归调用,保证 LLVM 不会出现 尾调用相关的问题。
2.4 XDP 转发性能
我们在 K8s 集群测试了 XDP 对 K8s Service 的转发。用 pktgen 生成 10Mpps 的入向处理流量,然后让 node 转发到位于其他节点的 backend pods。来看下几种不同的 负载均衡实现分别能处理多少。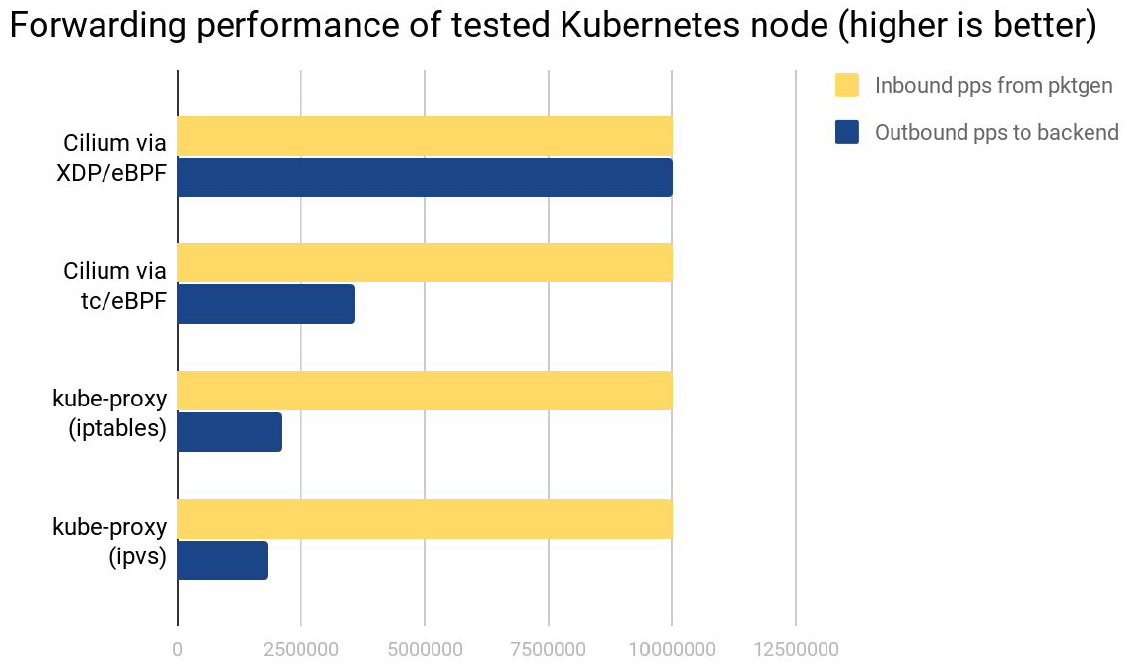
由上图可以看出,
- Cilium XDP 模式:能够处理全部的
10Mpps入向流量,将它们转发到其他节点上的 backend pods。 - Cilium TC 模式:可以处理大约
2.8Mpps,虽然它的处理逻辑和 Cilium XDP 是类似的(除了 BPF helpers)。 - kube-proxy iptables 模式:能处理
2.4Mpps,这是 K8s 的默认 Service 负载均衡实现。 - kube-proxy IPVS 模式:性能更差一些,因为它的 per-packet overhead 更大一些,这里测试的 Service 只对应一个 backend pod。当 Service 数量更多时, IPVS 的可扩展性更好,相比
iptables模式的kube-proxy性能会更好,但仍然没 法跟我们基于 TC BPF 和 XDP 的实现相比(no comparison at all)。
softirq 开销也是类似的,如下图所示,流量从 1Mpps 到 2Mpps 再到 4Mpps 时, XDP 模式下的 softirq 开销都远小于其他几种模式。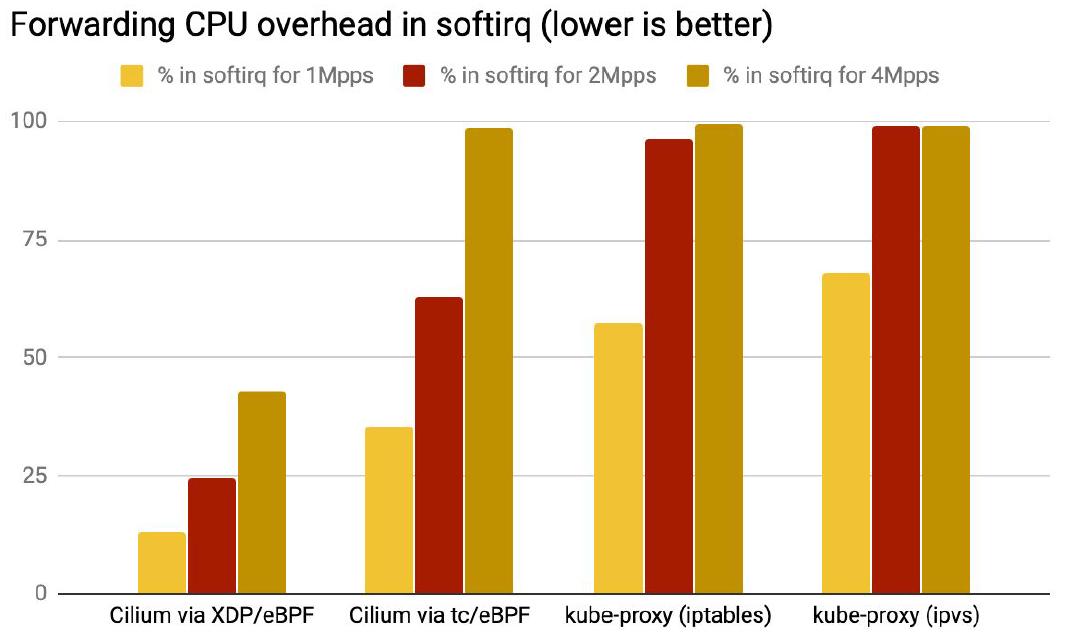
特别是 pps 到达某个临界点时,TC 和 Netfilter 实现中 softirq 开销会大到饱和 —— 占用几乎全部 CPU。
3 新的 BPF 内核扩展
下面介绍几个新的 BPF 内核扩展,主要是 Cilium 相关的场景。
3.1 避免穿越内核协议栈
主机收到的包,当其 backend 是本机上的 pod 时,或者包是本机产生的,目的端是一个本 机端口,这个包需要跨越不同的 netns,例如从宿主机的 netns 进入到容 器的 netns,现在 Cilium 的做法是,将包送到内核协议栈,如下图所示: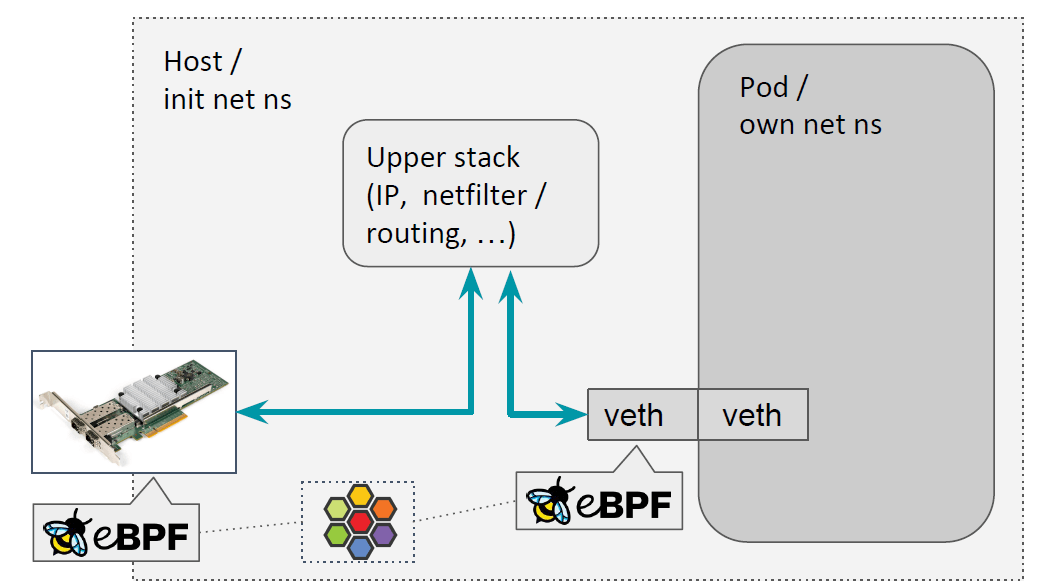
将包送到内核协议栈有两个原因(需要):
- TPROXY 需要由内核协议栈完成:我们目前的 L7 proxy 功能会用到这个功能,
- K8s 默认安装了一些 iptables rule,用来检测从连接跟踪的角度看是非法的连接(‘invalid’ connections on asymmetric paths),然后 netfilter 会 drop 这些连接 的包。我们最开始时曾尝试将包从宿主机 tc 层直接 redirect 到 veth,但应答包却要 经过协议栈,因此形成了非对称路径,流量被 drop。因此目前进和出都都要经过协议栈。
但这样带来两个问题,如下图所示: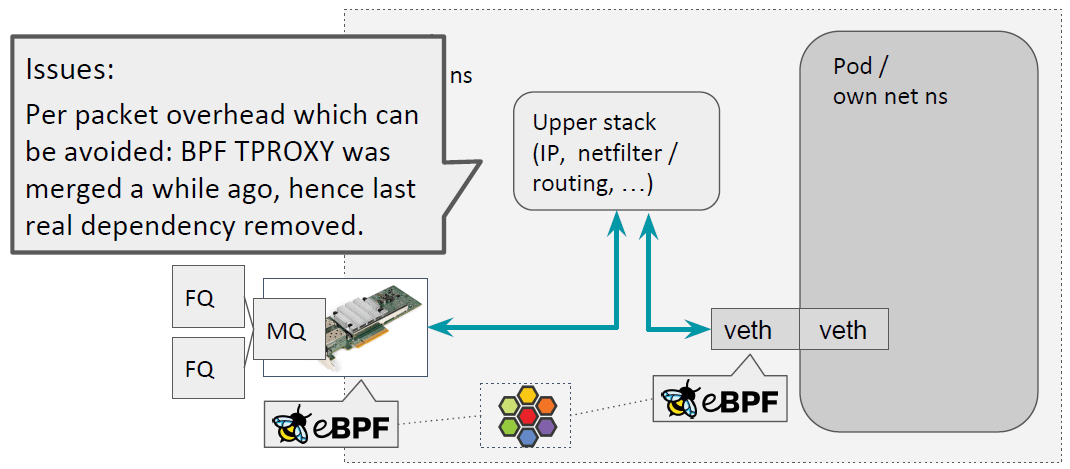
- Pod 的出向流量在进入协议栈后,在 socket buffer 层会丢掉 socket 信息(
skb->skgets orphaned atip_rcv_core()),这导致包从主机设备发出去时, 我们无法在 FQ leaf 获得 TCP 反压(TCP back-pressure)。 - 转发和处理都是 packet 级别的,因此有 per-packet overhead。
不久之前,BPF TPROXY 已经合并到内核,因此最后一个真正依赖 Netfilter 的东西已经 解决了。因此我们现在可以在 TC 层做全部逻辑处理了,无需进入内核协议栈,如下图所示: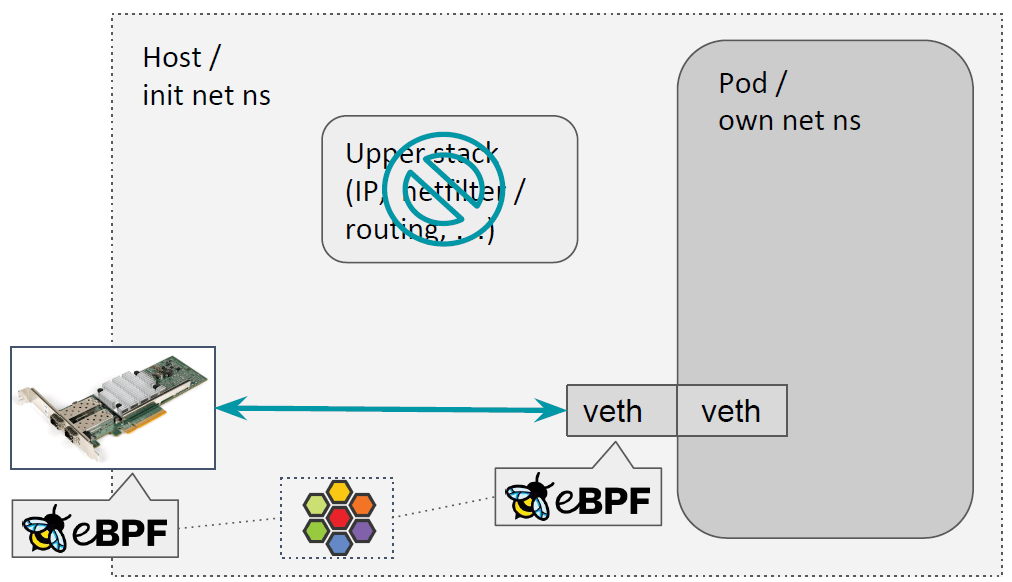
3.2 Redirection helpers
两个用于 redirection 的 TC BPF helpers:
bpf_redirect_neigh()bpf_redirect_peer()
从 IPVLAN driver 中借鉴了一些理念,实现到了 veth 驱动中。
3.2.1 Pod egress:bpf_redirect_neigh()
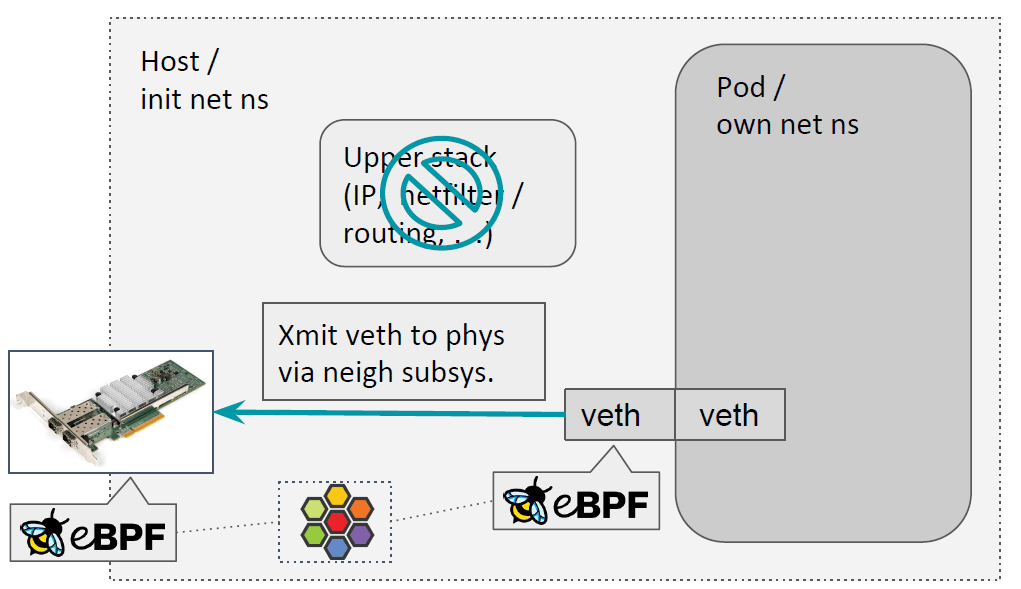
对于 pod egress 流量,我们会填充 src 和 dst mac 地址,这和原来 neighbor subsystem 做的事情相同;此外,我们还可以保留 skb 的 socket。这些都是由 bpf_redirect_neigh() 来完成的: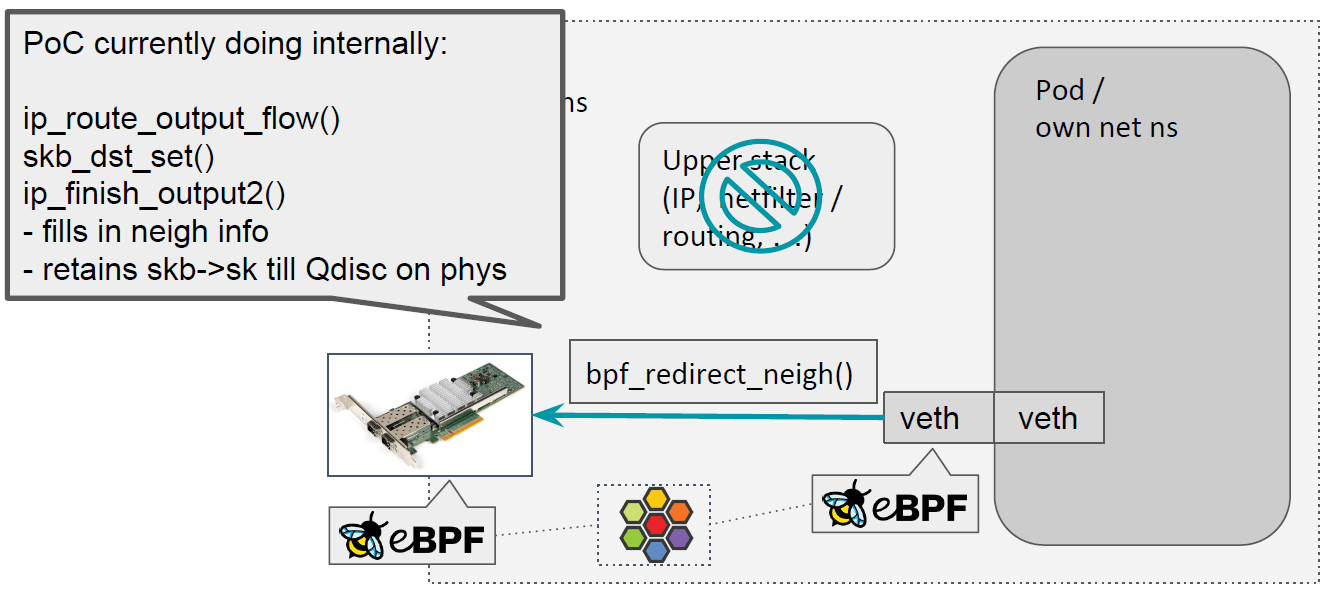
整个过程大致实现如下,在 veth 主机端的 ingress(对应 pod 的 egress)调用这 个方法的时候:
- 首先会查找路由,
ip_route_output_flow() - 将 skb 和匹配的路由条目(dst entry)关联起来,
skb_dst_set() - 然后调用到 neighbor 子系统,
ip_finish_output2()- 填充 neighbor 信息,即 src/dst MAC 地址
- 保留
skb->sk信息,因此物理网卡上的 qdisc 都能访问到这个字段
这就是 pod 出向的处理过程。
3.2.2 Pod ingress:bpf_redirect_peer()
入向流量,会有快速 netns 切换,从宿主机 netns 直接进入容器的 netns。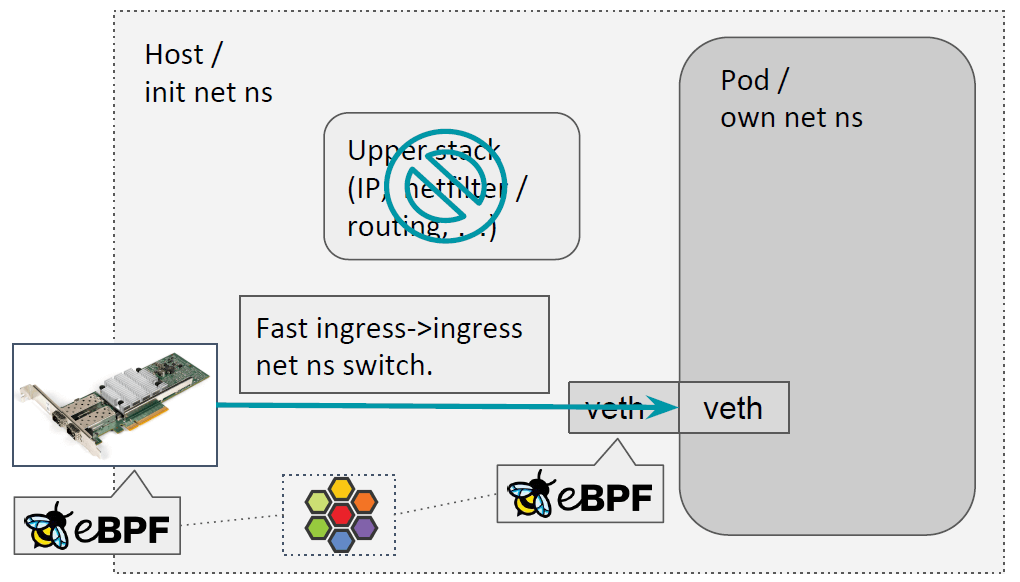
这是由 bpf_redirect_peer() 完成的。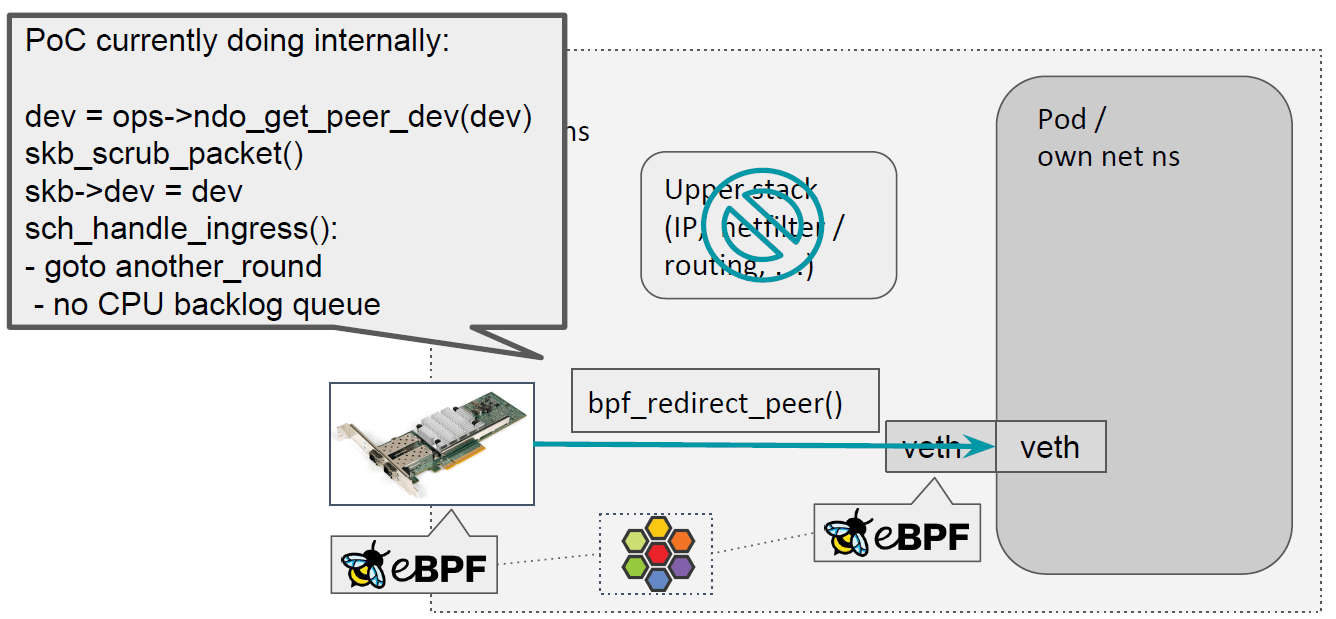
在主机设备的 ingress 执行这个 helper 的时候,
- 首先会获取对应的 veth pair,
dev = ops->ndo_get_peer_dev(dev),然后获取 veth 的对端(在另一个 netns) - 然后,
skb_scrub_packet() - 设置包的 dev 为容器内的 dev,
skb->dev = dev - 重新调度一次,
sch_handle_ingress(),这不会进入 CPU 的 backlog queue:- goto another_round
- no CPU backlog queue
3.2.3 veth to veth
同宿主机上的两个 Pod 之间通信时,这两个 helper 也非常有用。 因为我们已经在主机 netns 的 TC ingress 层了,因此能直接将其 redirect 到另一个容 器的 ingress 路径。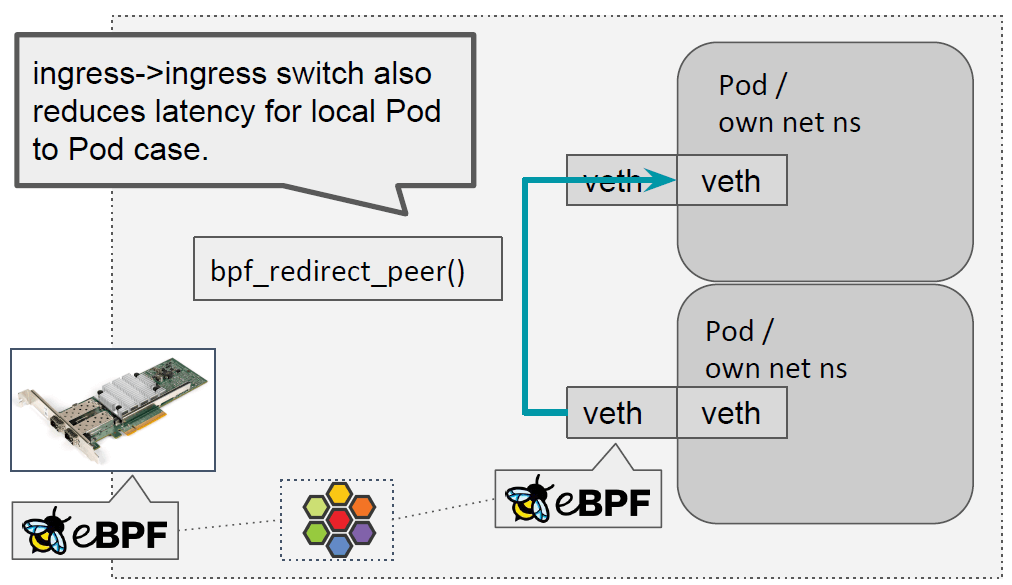
这里比较好的一点是,需要针对老版本内核所做的兼容性非常少;因此,我们只需要在启动的 时候检测内核是否有相应的 helper,
- 如果有,就用 redirection 功能;
- 如果没有,就直接返回 TC_OK,走传统的内核协议栈方式,经过内核邻居子系统。
支持这些功能无需对原有的 BPF datapath 进行大规模重构。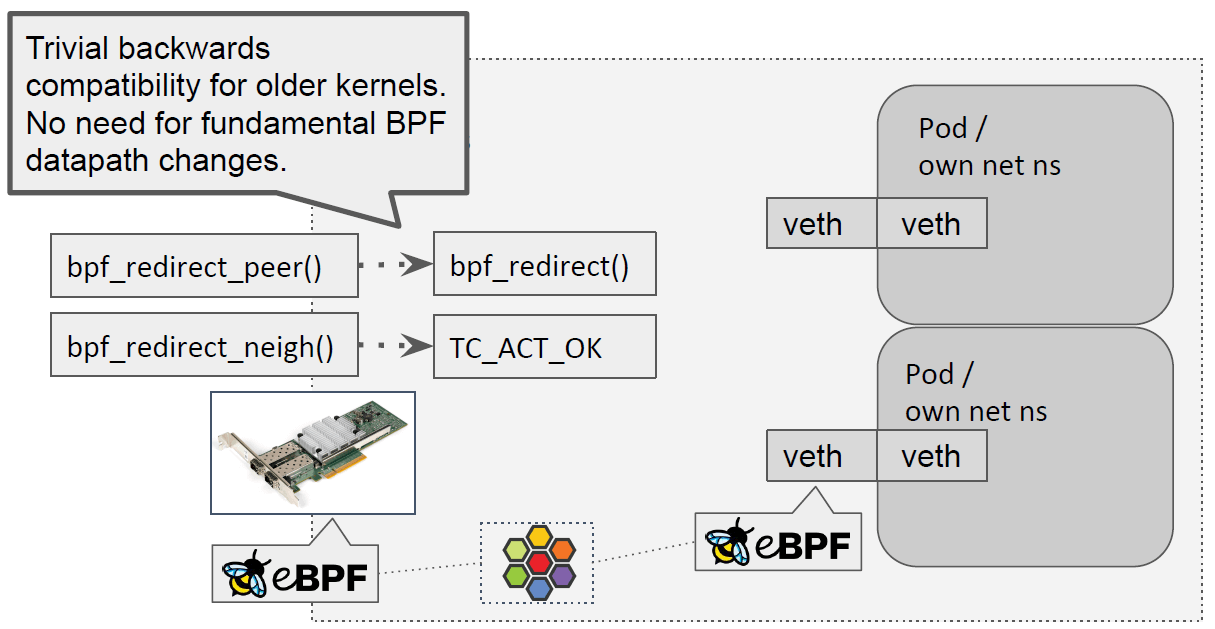
3.2.4 BPF redirection 性能
下面看下性能。
TCP stream 场景,相比 Cilium baseline,转发带宽增加了 1.3Gbps,接近线速: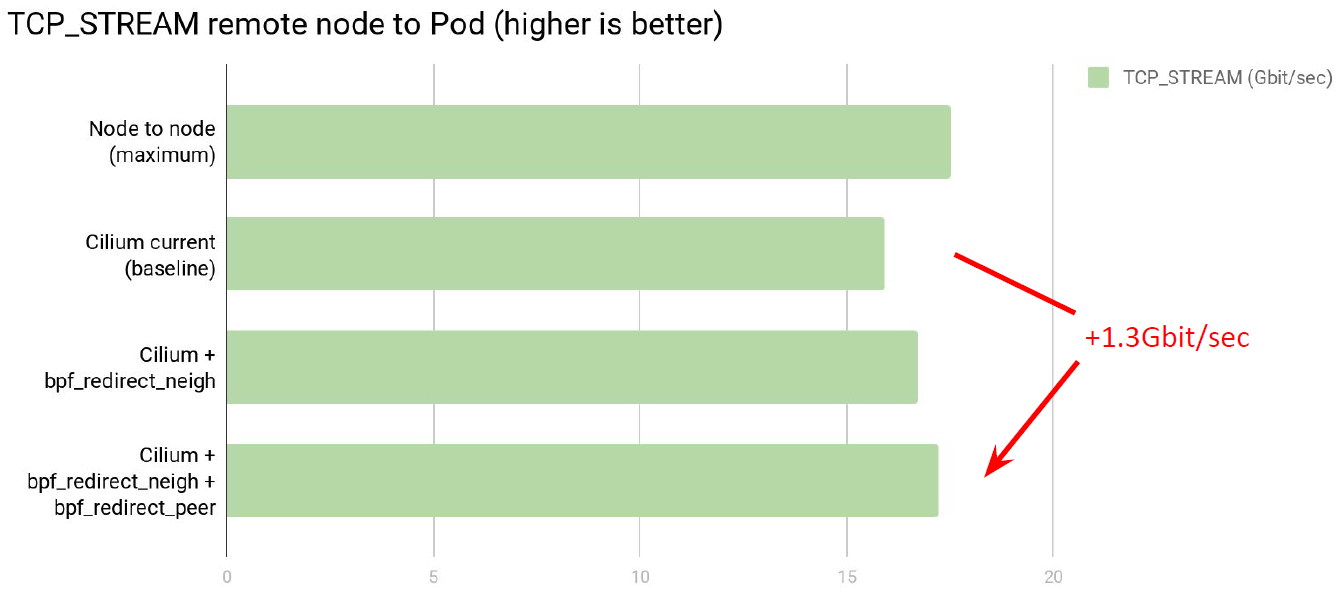
更有趣的是 TCP_RR 的场景,以 transactions/second 衡量,提升了 2.9 倍,接近最 大性能: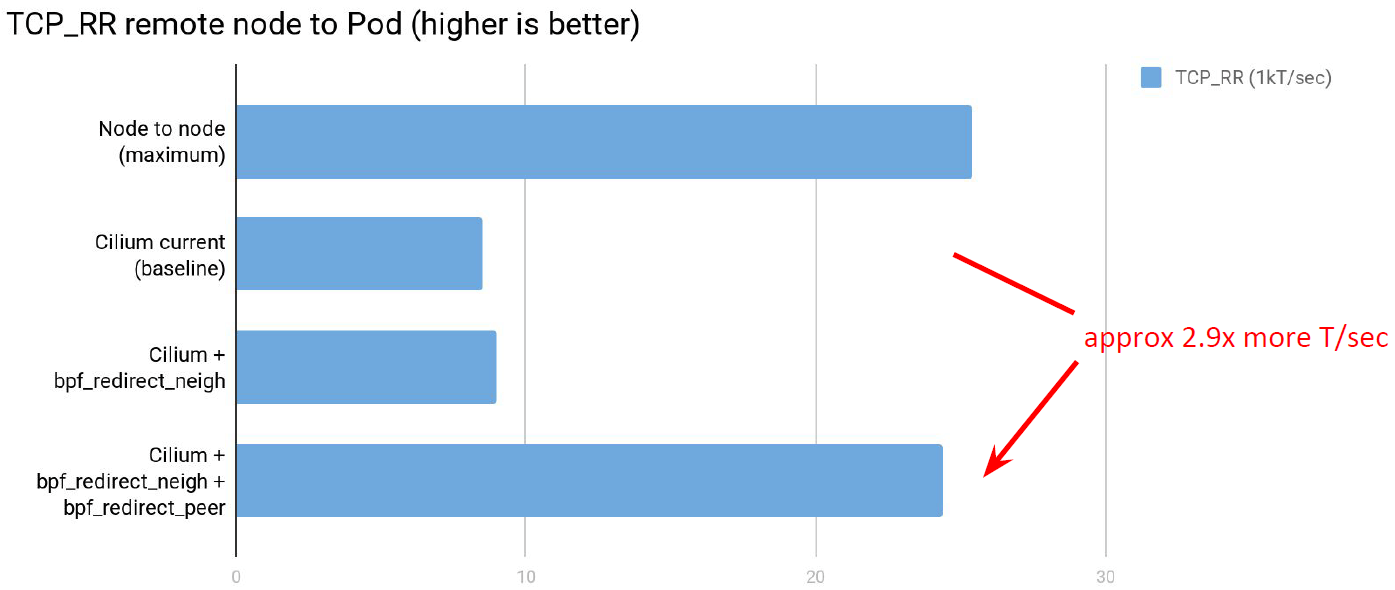
4 结束语

附录: plumbers_2020_cilium_load_balancer.pdf
译者:ArthurChiao 原文:https://linuxplumbersconf.org/event/7/contributions/674/