前言
之前介绍了 MaxScale 可以实现 Mysql 的读写分离和读负载均衡,那么当 slave 出现故障后,MaxScale 会如何处理呢?
例如有 3 台数据库服务器,一主二从的结构,数据库名称分别为 master, slave1, slave2
现在我们实验以下两种情况:
- 当一台从服务器( slave1 或者 slave2 )出现故障后,查看 MaxScale 如何应对,及故障服务器重新上线后的情况
- 当两台从服务器( slave1 和 slave2 )都出现故障后,查看 MaxScale 如何应对,及故障服务器重新上线后的情况
准备
为了更深入的查看 MaxScale 的状态,需要把 MaxScale 的日志打开
修改配置文件1
vi /etc/maxscale.cnf
找到 [maxscale] 部分,这里用来进行全局设置,在其中添加日志配置1
2log_info=1
logdir=/tmp/
通过开启 log_info 级别,可以看到 MaxScale 的路由日志
修改配置后,重启 MaxScale
实验过程
单个 slave 故障的情况
初始状态是一切正常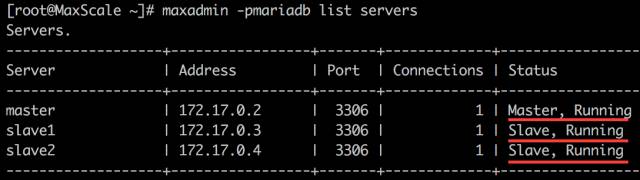
停掉 slave2 的复制,登录 slave2 的 mysql 执行1
mysql> stop slave;
查看 MaxScale 服务器状态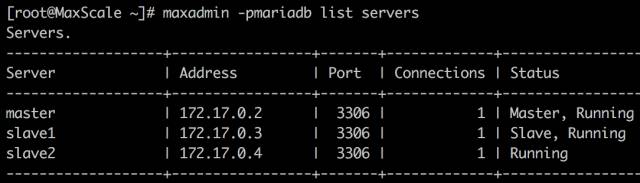
slave2 已经失效了
查看日志信息1
2
3cat /tmp/maxscale1.log
#尾部显示:
2016-08-15 12:26:02 notice : Server changed state: slave2[172.17.0.4:3306]: lost_slave
提示 slave2 已经丢失
查看客户端查询结果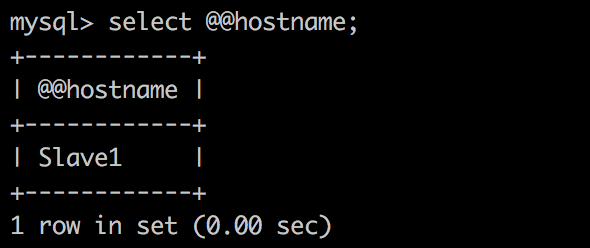
查询操作全都转到了 slave1
可以看到, 在有 slave 故障后,MaxScale 会自动进行排除,不再向其转发请求
下面看下 slave2 再次上线后的情况
登录 slave2 的 mysql 执行1
mysql> start slave;
查看 MaxScale 服务器状态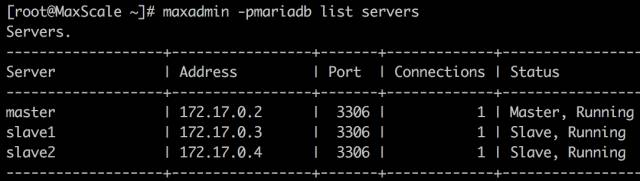
恢复了正常状态,重新识别到了 slave2
查看日志信息,显示:1
2016-08-15 12:32:36 notice : Server changed state: slave2[172.17.0.4:3306]: new_slave
查看客户端查询结果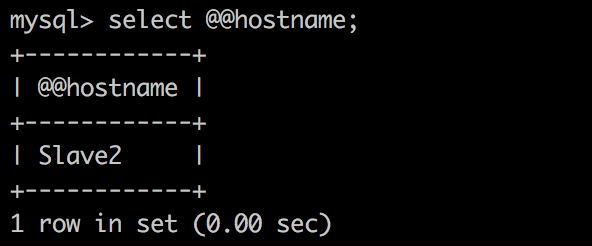
slave2 又可以正常接受查询请求
通过实验可以看到,在部分 slave 发生故障时,MaxScale 可以自动识别出来,并移除路由列表,当故障恢复重新上线后,MaxScale 也能自动将其加入路由,过程透明
全部 slave 故障的情况
分别登陆 slave1 和 slave2 的 mysql,执行停止复制的命令1
mysql> stop slave;
查看 MaxScale 服务器状态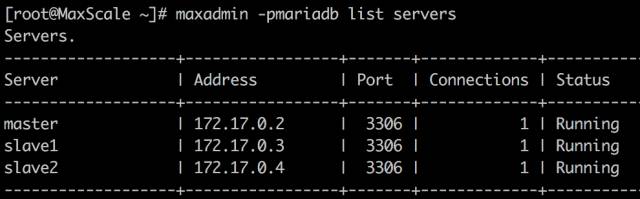
发现各个服务器的角色都识别不出来了
查看日志1
2
3
42016-08-15 12:44:11 notice : Server changed state: master[172.17.0.2:3306]: lost_master
2016-08-15 12:44:11 notice : Server changed state: slave1[172.17.0.3:3306]: lost_slave
2016-08-15 12:44:11 notice : Server changed state: slave2[172.17.0.4:3306]: lost_slave
2016-08-15 12:44:11 error : No Master can be determined. Last known was 172.17.0.2:3306
从日志中看到,MaxScale 发现2个slave 和 master 都丢了,然后报错:没有 master 了
客户端连接 MaxScale 时也失败了
说明从服务器全部失效后,会导致 master 也无法识别,使整个数据库服务都失效了
对于 slave 全部失效的情况,能否让 master 还可用?这样至少可以正常提供数据库服务
这需要修改 MaxScale 的配置,告诉 MaxScale 我们需要一个稳定的 master
处理过程
先恢复两个 slave,让集群回到正常状态,登陆两个 slave 的mysql1
mysql> start slave;
修改 MaxScale 配置文件,添加新的配置1
vi /etc/maxscale.cnf
找到 [MySQL Monitor] 部分,添加:1
detect_stale_master=true
保存退出,然后重启 MaxScale
验证
停掉两台 slave ,查看 MaxScale 服务器状态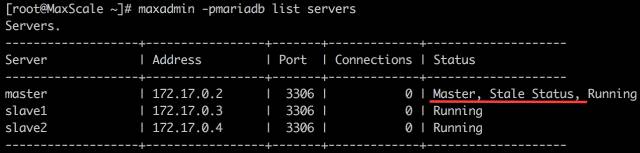
可以看到,虽然 slave 都无法识别了,但 master 还在,并提示处于稳定状态
客户端执行请求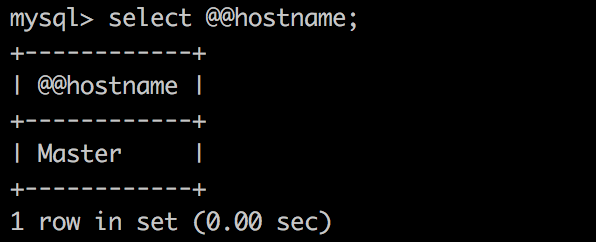
客户端可以连接 MaxScale,而且请求都转到了 master 上,说明 slave 全部失效时,由 master 支撑了全部请求
当恢复两个 slave 后,整体状态自动恢复正常,从客户端执行请求时,又可以转到 slave 上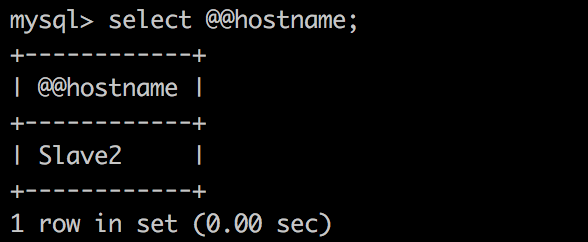
小结
通过测试发现,在部分 slave 故障情况下,对于客户端是完全透明的,当全部 slave 故障时,经过简单的配置,MaxScale 也可以很好的处理
来源:杜亦舒