前言
毫无疑问,我们希望正确处理客户端请求。当pod正在启动或关闭时,我们显然不希望看到断开的连接。Kubernetes本身并不能确保这种情况永远不会发生。您的应用需要遵循一些规则以防止断开连接。本文讨论这些规则。
确保正确处理所有客户端请求
我们先从访问Pod的客户端的视角来看看Pod的生命周期(客户端使用pod提供的服务)。我们希望确保客户的请求得到妥善处理,因为如果当pod启动或关闭时连接开始中断,我们就会遇到麻烦。Kubernetes本身并不保证不会发生这种情况,所以让我们看看我们需要做些什么来防止它发生。
当Pod启动时阻止连接中断
如果你理解services和service endpoints的工作原理,确保在pod启动时正确处理每个连接都非常简单。当pod启动时,它会作为一个endpoints被添加到所有匹配该Pod标签的Services里。Pod也会发出信号告诉Kubernetes它已就绪。只有它变成一个service endpoints时才可以接收来自客户端的请求。
如果你没有在Pod Spec里指定readiness探针,则会始终认为该pod已准备就绪。这意味着它将立即开始接收请求 - 只要第一个Kube-Proxy在其节点上更新iptables规则并且第一个客户端pod尝试连接到该服务。如果那个时候你的应用并没有做好接收请求的准备,那么客户端将会见到“connection refused”类型的错误。
你所需要做的就是保证你的readiness探针当且仅当你的应用可以正确处理收到的请求时才返回成功结果。所以添加一个HTTP GET readiness探针并让它指向你应用的基础URL会是一个很好的开始。在很多情况下,这可以让你省去实现一个特定的readiness端点的工作量。
在pod关闭期间防止断开连接
现在让我们看看当一个Pod生命周期结束时发生了什么——当Pod被删除和它里面的容器被停止时。一旦Pod的容器接收到SIGTERM后它就会开始关闭(或者是在那之前先执行prestop钩子),但这是否能保证所有的客户端请求可以被正确地处理?
我们的应用在收到结束信号时应该如何响应?它是否应该继续接收请求?那么那些已经收到的请求但是还未完成的请求呢?那么那些正在发送请求的间隔中且仍然处理打开状态的持久HTTP连接(连接上没有活跃的请求)呢?在回答这些问题之前,我们需要深入了解一下当Pod结束时集群里发生的一系列事件。
了解Pod删除时发生的一系列事件
您需要始终牢记Kubernetes的各个组件是独立运行在集群的节点上的。它们之间并不是一个巨大的单体应用。这些组件间同步状态会花费一点时间。让我们一起来看看当Pod删除时发生了什么。
当APIserver收到一个停止Pod的请求时,它首先修改了etcd里Pod的状态,并通知关注这个删除事件所有的watcher。这些watcher里包括Kubelet和Endpoint Controller。这两个序列的事件是并行发生的(标记为A和B),如图1所示。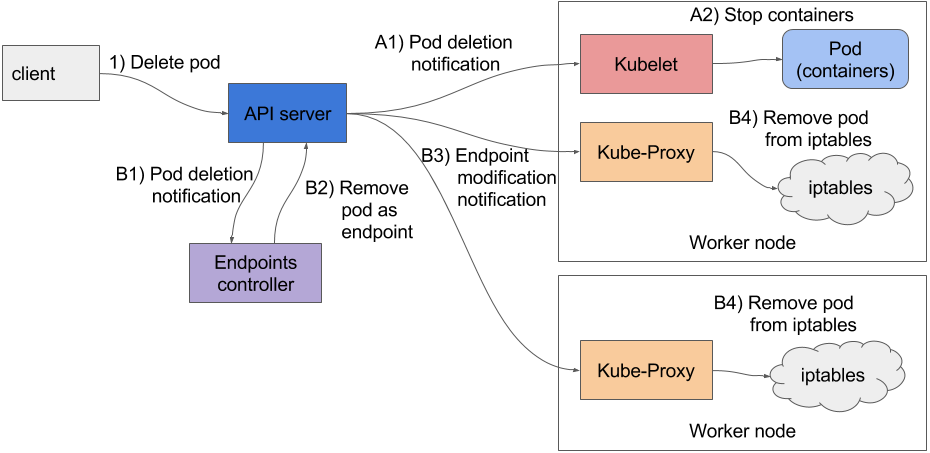
在A系列事件里,你会看到在Kubelet收到该Pod要停止的通知以后会尽快开始停止Pod的一系列操作(执行prestop钩子,发送SIGTERM信号,等待一段时间然后如果这个容器没有自动退出的话就强行杀掉这个容器)。如果应用响应了SIGTERM并迅速停止接收请求,那么任何尝试连接它的客户端都会收到一个Connection Refusd的错误。因为APIserver是直接向Kubelet发送的请求,那么从Pod被删除开始计算,Pod用于执行这段逻辑的时间相当短。
现在,让我们一起看看另外一系列事件都发生了什么——移除这个Pod相关的iptables规则(图中所示事件系列B)。当Endpoints Controller(运行在在Kubernetes控制平面里的Controller Manager里)收到这个Pod被删除的通知,然后它会把这个Pod从所有关联到这个Pod的Service里剔除。它通过向APIserver发送一个REST请求对Endpoint对象进行修改来实现。APIserver然后通知每个监视Endpoint对象的组件。在这些组件里包含了每个工作节点上运行的Kubeproxy。这些代理负责更新它所在节点上的iptables规则,这些规则可以用来阻止外面的请求被转发到要停止的Pod上。这里有个非常重要的细节,移除这些iptables规则对于已有的连接不会有任何影响——连接到这个Pod的客户端仍然可以通过已有连接向它发送请求。
这些请求都是并行发生的。更确切地,关停应用所需要的时间要比iptables更新花费所需的时间稍短一些。这是因为iptables修改的事件链看起来稍微长一些(见图2),因为这些事件需要先到达Endpoints Controller,然后它向APIServer发送一个新请求,接着在Proxy最终修改iptables规则之前,APIserver必须通知到每个KubeProxy。这意味着SIGTERM可能会在所有节点iptables规则更新前发送。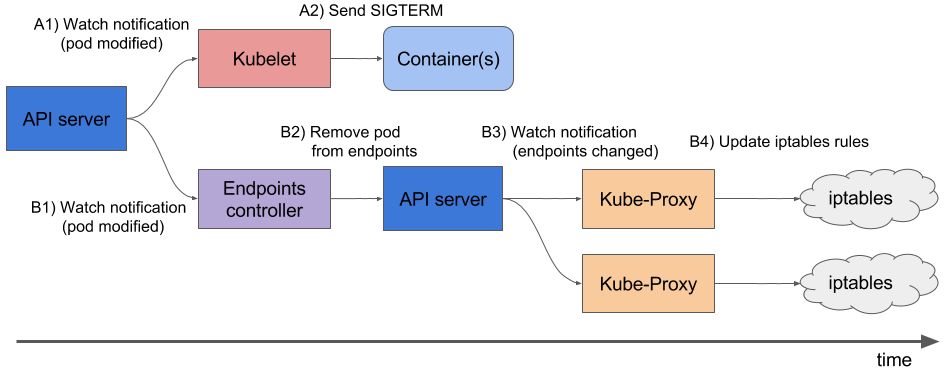
结果是pod在收到终止信号后仍然可以接收客户端请求。如果应用程序立即停止接受连接,则会导致客户端收到“Connection Refused”类型的错误(就像在没有定义Readiness探针时,Pod启动但无法对外提供服务时一样) 。
解决问题
谷歌搜索此问题的解决方案,似乎给Pod添加一个Readiness探针就可以解决这个问题。按照推测,你所需要做的就是让你的Readiness探针在应用收到SIGTERM信号后尽快失败。这可以让Pod从Service上移除。只有在Readiness探针连续失败几次后才会从Service上移除(这可以在Readiness探针里进行配置)。并且显然这个移除事件会在iptables规则更新前先到达Kubeproxy。
实际上,Readiness探针在整个过程中并未起到关键作用。一旦Endpoints Controller收到Pod删除事件后(当Pod配置里的deletionTimestamp域不再为空时),它会尽快从Service上移除这些Pod。从那时起,这已经就与Readiness探测结果不相关了。
那么什么是问题的正确解决方案?我们如何保证所有的请求都可以被正确处理?
好吧,很明显,即使收到终止信号后,pod也需要继续接受连接,直到所有Kube代理完成更新iptables规则。那么,不止是Kubeproxy。可能有一些IngressController或者其他直接向Pod转发请求的负载均衡设备等不需要经过Service的。这还包括使用客户端负载平衡的客户端。
为了确保没有任何客户端遇到断开的连接,您必须等到所有客户端以某种方式通知您他们将不再转发到该Pod的连接。
但这是不可能的,因为这些组件都分布在不同的计算机上。即使你知道它们每个所在的位置或者等着它们每个都满足停止Pod的需求,如果它们其中之一没有响应你会该怎么办?你要等待多久?记着,在那段时间里,你需要暂停关闭进程。
你唯一可能的做事情是你可以等待足够长的时间直到所有的代理都完成了它们的工作。但是多长时间才算够?在大多数情况中,短暂的几秒就足够了,但是显然这并不能满足全部的情况。当APIserver或者Endpoints Controller过载时,它们可能需要更长时间来通知到每个代理。重要的是要了解您无法完美地解决问题,但是即使是5秒或者10秒都可以显著提升用户体验。你可以设置更长的延迟,但是别太过分,因为这些延迟推迟了容器的停止时间,并且会导致容器在被关停后仍然被显示在列表里,这会对用户带来一定的困扰。
正确关闭应用程序包括以下步骤:
- 等待几秒,然后停止接收新连接
- 关闭所有未在请求中的keep-alived连接
- 等到所有活跃的请求关闭,然后
- 彻底关闭
要了解在此过程中连接和请求发生的情况,请仔细检查图3。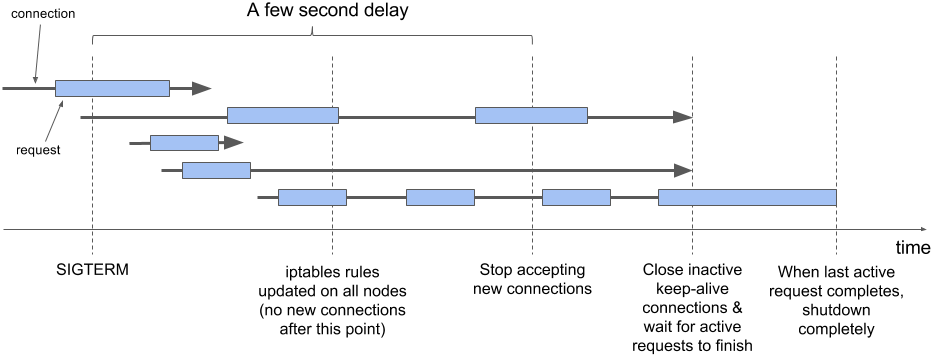
没有像收到终止信号后立即退出过程一样简单,对吧?这一切是值得的吗?这要靠你自己来决定。但是至少你可以添加一个prestop钩子并等待几秒,就像下面所示:1
2
3
4
5
6
7lifecycle:
preStop:
exec:
command:
- sh
- -c
- "sleep 5"
这样,您根本不需要修改应用程序的代码。如果您的应用要确保完全处理所有正在进行的请求,这个preStop钩子就可以满足所有你的需要。
参考文档:
- handling-client-requests-properly-with-kubernetes