前言
QoS是 Quality of Service 的缩写,即服务质量。为了实现资源被有效调度和分配的同时提高资源利用率,kubernetes针对不同服务质量的预期,通过 QoS(Quality of Service)来对 pod 进行服务质量管理。对于一个 pod 来说,服务质量体现在两个具体的指标:CPU 和内存。当节点上内存资源紧张时,kubernetes 会根据预先设置的不同 QoS 类别进行相应处理。
QoS 主要分为Guaranteed、Burstable 和 Best-Effort三类,优先级从高到低。
Guaranteed(有保证的)
对于绑定 CPU 和具有相对可预测性的工作负载(例如,用来处理请求的 Web 服务)来说,这是一个很好的 QoS 等级。属于该级别的pod有以下两种:
- Pod中的所有容器都且仅设置了 CPU 和内存的 limits
- pod中的所有容器都设置了 CPU 和内存的 requests 和 limits ,且单个容器内的requests==limits(requests不等于0)
示例1:pod中的所有容器都且仅设置了limits
1
2
3
4
5
6
7
8
9
10
11containers:
name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
name: bar
resources:
limits:
cpu: 100m
memory: 100Mi
示例2: pod 中的所有容器都设置了 requests 和 limits,且单个容器内的requests==limits1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18containers:
name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
requests:
cpu: 10m
memory: 1Gi
name: bar
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
容器foo和bar内resources的requests和limits均相等,该pod的QoS级别属于Guaranteed。
Burstable(不稳定的)
这对短时间内需要消耗大量资源或者初始化过程很密集的工作负载非常有用,例如:用来构建 Docker 容器的 Worker 和运行未优化的 JVM 进程的容器都可以使用该 QoS 等级。pod中只要有一个容器的requests和limits的设置不相同,该pod的QoS即为Burstable。
示例1:容器foo指定了resource,而容器bar未指定1
2
3
4
5
6
7
8
9
10
11containers:
name: foo
resources:
limits:
cpu: 10m
memory: 1Gi
requests:
cpu: 10m
memory: 1Gi
name: bar
示例2:容器foo设置了内存limits,而容器bar设置了CPU limits1
2
3
4
5
6
7
8
9
10containers:
name: foo
resources:
limits:
memory: 1Gi
name: bar
resources:
limits:
cpu: 100m
注意:若容器指定了requests而未指定limits,则limits的值等于节点resource的最大值;若容器指定了limits而未指定requests,则requests的值等于limits。
Best-Effort(尽最大努力)
这对于可中断和低优先级的工作负载非常有用,例如:迭代运行的幂等优化过程。如果Pod中所有容器的resources均未设置requests与limits,该pod的QoS即为Best-Effort。
示例1:容器foo和容器bar均未设置requests和limits1
2
3
4
5containers:
name: foo
resources:
name: bar
resources:
根据QoS进行资源回收策略
Kubernetes 通过cgroup给pod设置QoS级别,当资源不足时先kill优先级低的 pod,在实际使用过程中,通过OOM分数值来实现,OOM分数值范围为0-1000。OOM 分数值根据OOM_ADJ参数计算得出。
对于Guaranteed级别的 Pod,OOM_ADJ参数设置成了-998,对于Best-Effort级别的 Pod,OOM_ADJ参数设置成了1000,对于Burstable级别的 Pod,OOM_ADJ参数取值从2到999。
对于 kuberntes 保留资源,比如kubelet,docker,OOM_ADJ参数设置成了-999,表示不会被OOM kill掉。OOM_ADJ参数设置的越大,计算出来的OOM分数越高,表明该pod优先级就越低,当出现资源竞争时会越早被kill掉,对于OOM_ADJ参数是-999的表示kubernetes永远不会因为OOM将其kill掉。
QoS pods被kill掉场景与顺序
Best-Effort pods:系统用完了全部内存时,该类型 pods 会最先被kill掉。Burstable pods:系统用完了全部内存,且没有 Best-Effort 类型的容器可以被 kill 时,该类型的 pods 会被 kill 掉。Guaranteed pods:系统用完了全部内存,且没有 Burstable 与 Best-Effort 类型的容器可以被 kill 时,该类型的 pods 会被 kill 掉。
QoS使用建议
如果资源充足,可将 QoS pods 类型均设置为Guaranteed。用计算资源换业务性能和稳定性,减少排查问题时间和成本。如果想更好的提高资源利用率,业务服务可以设置为Guaranteed,而其他服务根据重要程度可分别设置为Burstable或Best-Effort。
在搞清楚服务什么时候会出现故障以及为什么会出现故障之前,都不应该将其部署到生产环境中。可通过一些技术手段(负载压测等)来设置应用的资源 limits 和 requests。这将会为你的系统增加弹性能力和可预测性。
在测试过程中,记录服务失败时做了哪些操作是至关重要的。可以将发现的故障模式添加到相关的书籍和文档中,这对分类生产环境中出现的问题很有用。下面是我们在测试过程中发现的一些故障模式:
- 内存缓慢增加
- CPU 使用率达到 100%
- 响应时间太长
- 请求被丢弃
- 不同请求的响应时间差异很大
你最好将这些发现都收集起来,以备不时之需,因为有一天它们可能会为你或团队节省一整天的时间。
一些有用的工具
Loader.io
Loader.io 是一个在线负载测试工具,它允许你配置负载增加测试和负载不变测试,在测试过程中可视化应用程序的性能和负载,并能快速启动和停止测试。它也会保存测试结果的历史记录,因此在资源限制发生变化时很容易对结果进行比较。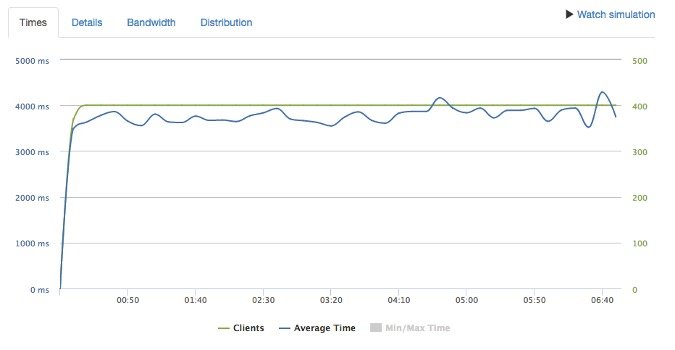
Kubescope cli
Kubescope cli 是一个可以运行在本地或 Kubernetes 中的工具,可直接从 Docker Daemon 中收集容器指标并可视化。和 cAdvisor 等其他集群指标收集服务一样, kubescope cli 收集指标的周期是 1 秒(而不是 10-15 秒)。如果周期是 10-15 秒,你可能会在测试期间错过一些引发性能瓶颈的问题。如果你使用 cAdvisor 进行测试,每次都要使用新的 Pod 作为测试对象,因为 Kubernetes 在超过资源限制时就会将 Pod 杀死,然后重新启动一个全新的 Pod。而 kubescope cli 就没有这方面的忧虑,它直接从 Docker Daemon 中收集容器指标(你可以自定义收集指标的时间间隔),并使用正则表达式来选择和过滤你想要显示的容器。
来源:
- 阳明的博客
- Ryan Yang