问题概要
上周我们将一个微服务迁移到中央平台上,包括CI/CD,Kubernetes运行时,metric和其他一些程序。这次实验是为了之后一个月里大概150个微服务的迁移作准备,所有这些服务支撑着西班牙在线市场的运营。
当我们将应用程序部署到Kubernetes上,并且将一些生产流量导入其中之后,事情开始有些不妙了。Kubernetes上的请求延迟比EC2上的高10倍左右。除非我们能找到解决方案,不然这会是微服务迁移的最大障碍,甚至可能彻底摧毁整个项目。
为什么Kubernetes上的延时比EC2高那么多?
为了找到系统瓶颈,我们收集了整个请求路径的metric。架构很简单,一个API网关(Zuul)将请求路由到EC2或者Kubernetes的微服务里。在Kubernetes上,我们使用NGINX Ingress控制器,后台是常规的Deployment运行一个基于Spring的JVM应用程序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19 EC2
+---------------+
| +---------+ |
| | | |
+-------> BACKEND | |
| | | | |
| | +---------+ |
| +---------------+
+------+ |
Public | | |
-------> ZUUL +--+
traffic | | | Kubernetes
+------+ | +-----------------------------+
| | +-------+ +---------+ |
| | | | xx | | |
+-------> NGINX +------> BACKEND | |
| | | xx | | |
| +-------+ +---------+ |
+-----------------------------+
问题看上去是后台的上游延迟(上图用xx表示)。当应用程序部署在EC2上时,响应时间大概20ms。在Kubernetes上则需要100~200ms。
我们很快排除了运行时变更的影响。JVM版本是一致的。容器化的影响也被排除了,因为EC2上也是运行在容器里。也和压力无关,因为即使每秒只有1个请求仍然能看到很高的延时。也不是GC的影响。
一个Kubernetes管理员问应用程序是否有外部的依赖,比如以前DNS解析曾经导致过类似的问题,这是目前为止最可能的猜想。
猜想1:DNS解析
每次请求里,我们的应用程序会向AWS ElasticSearch实例(域名类似 elastic.spain.adevinta.com)发送1~3次请求。我们在容器内放置了一个shell脚本可以验证这个域名从DNS解析需要多长时间。
容器内的DNS查询:1
2
3
4
5
6
7
8[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 22 msec
;; Query time: 22 msec
;; Query time: 29 msec
;; Query time: 21 msec
;; Query time: 28 msec
;; Query time: 43 msec
;; Query time: 43 msec
运行着对应相同用程序的EC2实例里的同样的查询:1
2
3
4
5
6bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
;; Query time: 77 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
;; Query time: 0 msec
大概30ms的解析时间,似乎我们的应用程序在和ElasticSearch通信时增加了DNS解析的额外消耗。
但是这里有两点很奇怪:
- 在Kubernetes里已经有很多应用程序和AWS资源通信,但是并没有这个问题。
- 我们知道JVM实现了内存内的DNS缓存。查看这些镜像的配置,在 $JAVA_HOME/jre/lib/security/java.security里配置了TTL为 networkaddress.cache.ttl=10。JVM应该能够缓存10秒内的所有DNS查询。
为了确认是DNS的影响,我们决定避免DNS解析并且查看问题是否会消失。首先尝试让应用程序直接和Elasticsearch的IP通信,而不是域名。这要求代码变更并且重新部署,因此我们只是简单地在 /etc/hosts文件里添加了域名和IP的映射:1
34.55.5.111 elastic.spain.adevinta.com
这样容器可以立刻解析IP。我们确实观察到了延时的改善,但是离我们的最终目标还是很远。即使DNS解析足够快,但是真实原因还是没有找到。
网络plumbing
我们决定在容器里执行 tcpdump,这样可以看到网络到底干了些什么。1
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap
然后发送了一些请求并且下载了capture文件( kubectl cpmy-service:/capture.pcap capture.pcap)在Wireshark里查看。
DNS查询看上去很正常(除了一些细节,之后会提到)但是我们的服务处理请求的时候很奇怪。下图是capture的截图,显示一个请求从开始到响应的全过程。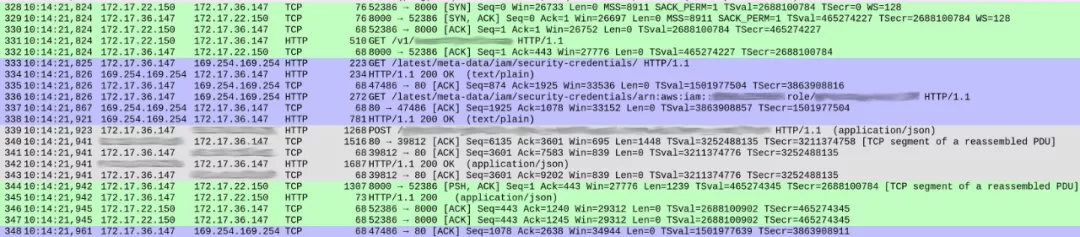
第一列是packet序号。我用不同的颜色标示不同的TCP流。
绿色的流从packet 328开始,显示客户端(172.17.22.150)开启了容器(172.17.36.147)的TCP连接。最初的握手(328-330)之后,packet 331开始 HTTP GET/v1/..,这是对我们自己服务的入站请求。整个流程花了1ms。
灰色流从packet 339开始,展示了我们的服务发送一个HTTP请求给Elasticsearch实例(这里看不到TCP握手过程因为它使用了一个已有的TCP连接)。这里花了18ms。
至此都没有什么问题,所花的时间和预计差不多(~20-30ms)。
但是在这两次交互之间,紫色部分花了86ms。这里发生了什么?在packet 333, 我们的服务发送了HTTP GET到 /latest/meta-data/iam/security-credentials,之后,在同一个TCP连接里,另一个GET发送到 /latest/meta-data/iam/security-credentials/arn:..。
我们发现每次请求里都会这样做。DNS解析在容器里确实有一点慢(解释很有意思,我会在另一篇文章里介绍)。但是高延迟的实际原因是每次请求里对AWS Instance Metadata的查询。
猜想2:AWS调用
这两个endpoint都是AWS Instance Metadata API的一部分。我们的微服务从Elasticsearch里读取时会用到这个服务。这两个调用都是基础的授权工作流。
第一个请求里查询的endpoint得到和该实例相关联的IAM角色。1
2/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
arn:aws:iam::<account_id>:role/some_role
第二个请求查询第二个endpoint得到该实例的临时credential。1
2
3
4
5
6
7
8
9
10/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role
{
"Code": "Success",
"LastUpdated": "2012-04-26T16:39:16Z",
"Type": "AWS-HMAC",
"AccessKeyId": "ASIAIOSFODNN7EXAMPLE",
"SecretAccessKey": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"Token": "token",
"Expiration": "2017-05-17T15:09:54Z"
}
客户端可以在短时间内使用它们,并且需要周期性地(在 Expiration之前)去获取新的credencial。模型很简单:AWS为了安全考虑经常轮询临时密钥,但是客户端可以将密钥缓存几分钟来弥补获得新credencial所带来的性能影响。
AWS Java SDK应该处理这些,但是,因为某种原因,它没有这么做。
在GitHub issue里搜索后找到了#1921,里面有我们需要的线索。
AWS SDK在下面两种情况的某一种满足时就会刷新credential:
- Expiration在 EXPIRATION_THRESHOLD内,硬编码为15分钟。
- 前一次刷新credential的尝试所花时间大于 REFRESH_THRESHOLD,硬编码为60分钟。
我们需要查看得到的证书里的实际过期时间,因此运行了两个 cURL命令调用AWS API,一次从容器里,一次从EC2实例里。从容器里获得的证书过期时间短得多,是15分钟。
问题变得清晰了:我们的服务在第一个请求里会获取临时credential。因为它有15分钟的过期时间,在下一次请求里,AWS SDK会重新刷新credential。每次请求都会这样。
为什么credential过期时间变短了?
AWS Intance Metadata Service设计上是在EC2实例里使用,而不是Kubernetes上。我们希望应用程序保留相同的接口。因此使用了Kiam,在每个Kubernetes节点上运行一个agent,允许用户(部署应用程序到集群里的工程师)将IAM角色关联到Pod容器上,就像它是个EC2实例一样。它会截获发送到AWS Instance Metadata服务的调用,并且使用agent提前从AWS获取并放在缓存里的内容响应。从应用程序的角度来看,和运行在EC2上没什么区别。
Kiam给Pod提供的正是短期的credencial,这有道理,因为它假定Pod的平均生命周期比EC2实例要短。默认值就是15分钟。
但是如果两处都使用默认值就有问题了。提供给应用程序的证书过期时间为15分钟。AWS Java SDK会强制刷新任何过期时间少于15分钟的证书。
结果就是每个请求都会强制刷新临时证书,这需要两次调用AWS API,给每次请求都带来了巨大的延迟。之后我们找到了AWS Java SDK的一个功能请求,里面提到了同样的问题。
解决办法很简单,我们重新配置了Kiam,请求更长过期时间的credencial。当这一变更生效后,请求就不用每次都调用AWS Metadata服务了,而且延迟比EC2还要小。
收获
从我们迁移的经验里,最经常遇到的问题不是Kubernetes的bug或者平台的问题。也不是微服务本身的问题。问题通常只是因为集成。我们将以前从来没有一起集成过的复杂系统混合在一起,并且期望它们组成单个的大系统。可移动组件越多,可能发生问题的地方就越多。
在这个问题里,高延迟并不是因为bug或者Kubernetes、Kiam、AWS Java SDK或我们自己微服务本身有什么问题。它是Kiam和AWS Java SDK里两个独立的默认值组合在一起导致的问题。独立来看,两个默认值都没什么问题:AWS Java SDK强制credential刷新策略和Kiam比较低的默认过期时间。但是组合起来就导致了问题。两个单独看都是正确的决定合在一起并不一定是正确的。
如果使用的是aws的eks,现在可以不用使用kiam这个插件来实现role访问aws服务,aws eks 实现了service accounts 与 role 绑定,具体参考:https://docs.aws.amazon.com/zh_cn/eks/latest/userguide/iam-roles-for-service-accounts.html
来源:kubernetes-added-a-0-to-my-latency