KinD 是一个非常轻量级的 Kubernetes 安装工具,他将 Docker 容器当成 Kubernetes 的节点,使用非常方便。既然在 Docker 容器中可以运行 Kubernetes 集群,那么我们自然就会想到是否可以在 Pod 中来运行呢?在 Pod 中运行会遇到哪些问题呢?
在 Pod 中安装 Docker Daemon
KIND 当前依赖于 Docker(尽管他们计划很快支持其他容器运行时,例如podman)。因此,第一步是创建一个容器映像,该映像允许您在 Pod 内运行 Docker守护程序,以便使诸如docker run之类的命令在Pod内运行(又名 Docker-in-Docker 或 DIND )。
Docker-in-Docker 是一个众所周知的问题,并且已经解决了相当一段时间。尽管如此,当尝试在生产 Kubernetes 集群中正确设置 Docker-in-Docker 时,我们仍然遇到很多问题。
MTU问题
MTU 问题的性质实际上取决于生产 Kubernetes 集群的网络提供商。我们用于 CI 的Kubernetes 发行版是 Konvoy。Konvoy 使用Calico作为其默认网络提供商,并且默认情况下使用IPIP封装。IPIP封装产生20字节的开销。换句话说,如果群集中主机网络的主网络接口的MTU为1500,则Pod中网络接口的MTU将为1480。如果您的生产群集在某些云提供商(例如GCE)上运行,则MTU Pod的最大值甚至更低(1460-20 = 1440)。
重要的是,我们在 Pod 内配置默认 Docker 网络的MTU(dockerd 的 --mtu标志),使其等于或小于 Pod 的网络接口的MTU。否则,您将无法与外界建立连接(例如,从互联网上获取容器图像时)。
PID 1 的问题
比如我们需要在一个容器中去运行 Docker Daemon 以及一些 Kubernetes 的集群测试,而这些测试依赖于 KinD 和 Docker Damon,在一个容器中运行多个服务我们可能会去使用 systemd,但是使用 systemd 也会有一些问题。
比如我们需要保留测试的退出状态,Kubernetes 中使用的容器运行时可以 watch 到容器中的第一个进程(PID 1)的退出状态。如果我们使用 systemd 的话,那么我们测试的进程退出状态不会被转发到 Kubernetes。
此外获取测试的日志也是非常重要的,在 Kubernetes 中会自动获取写入到 stdout 和 stderr 的容器日志,但是如果使用 systemd 的话,要想获取应用的日志就比较麻烦的。
为了解决上面的问题,我们可以在容器镜像中使用如下所示的启动脚本:1
2
3
4
5
6
7
8dockerd &
# Wait until dockerd is ready.
until docker ps >/dev/null 2>&1
do
echo "Waiting for dockerd..."
sleep 1
done
exec "$@"
但是需要注意的是我们不能将上面的脚本作为容器的 entrypoint,在镜像中定义的 entrypoint 会在容器中以 PID 1 的形式运行在一个单独的 pid namespace 中。PID 1 是一个内核中的一个特殊进程,它的行为和其他进程不同。
本质上,接收信号的进程是 PID 1:它会被内核做特殊处理;如果它没有为信号注册一个处理器,内核就不会回到默认行为(即杀死进程)。由于当收到 SIGTERM 信号时,内核会默认杀死这个进程,所以一些进程也许不会为 SIGTERM 信号注册信号处理程序。如果出现了这种情况,当 Kubernetes 尝试终止 Pod 时,SIGTERM 将被吞噬,你会注意到 Pod 会被卡在 Terminating 的状态下。
这其实不是一个什么新鲜的问题,但是了解这个问题的人却并不多,而且还一直在构建有这样问题的容器。我们可以使用 tini 这个应用来解决这个问题,将其作为镜像的入口点,如在 Dockerfile 中所示:1
ENTRYPOINT ["/usr/bin/tini", "--", "/entrypoint.sh"]
这个程序会正确注册信号处理程序和转发信号。它还会执行一些其他 PID 1 的事情,比如回收容器中的僵尸进程。
挂载 cgroups
由于 Docker Daemon 需要控制 cgroups,所以需要将 cgroup 文件系统挂载到容器中去。但是由于 cgroups 和宿主机是共享的,所以我们需要确保 Docker Daemon 控制的 cgroups 不会影响到其他容器或者宿主机进程使用的其他 cgroups,还需要确保 Docker Daemon 在容器中创建的 cgroups 在容器退出后不会被泄露。
Docker Daemon 中有一个 --cgroup—parent 参数来告诉 Daemon 将所有容器的 cgroups 嵌套在指定的 cgroup 下面。当容器运行在 Kubernetes 集群下面时,我们在容器中设置 Docker Daemon 的 --cgroup—parent 参数,这样它的所有 cgroups 就会被嵌套在 Kubernetes 为容器创建的 cgroup 下面了。
在以前为了让 cgroup 文件系统在容器中可用,一些用户会将宿主机中的 /sys/fs/cgroup 挂载到容器中的这个位置,如果这样使用的话,我们就需要在容器启动脚本中把 --cgroup—parent 设置为下面的内容,这样 Docker Daemon 创建的 cgroups 就可以正确被嵌套了。1
CGROUP_PARENT="$(grep systemd /proc/self/cgroup | cut -d: -f3)/docker"
注意:
/proc/self/cgroup显示的是调用进程的 cgroup 路径。
但是我们要知道,挂载宿主机的 /sys/fs/cgroup 文件是非常危险的事情,因为他把整个宿主机的 cgroup 层次结构都暴露给了容器。以前为了解决这个问题,Docker 用了一个小技巧把不相关的 cgroups 隐藏起来,不让容器看到。Docker 从容器的 cgroups 对每个 cgroup 系统的 cgroup 层次结构的根部进行绑定挂载。1
2
3
4
5
6
7
8
9$ docker run --rm debian findmnt -lo source,target -t cgroup
SOURCE TARGET
cpuset[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/cpuset
cpu[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/cpu
cpuacct[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/cpuacct
blkio[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/blkio
memory[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/memory
cgroup[/docker/451b803b3cd7cd2b69dde64cd833fdd799ae16f9d2d942386ec382f6d55bffac] /sys/fs/cgroup/systemd
从上面我们可以看出 cgroups 通过将宿主机 cgroup 文件系统上的 /sys/fs/cgroup/memory/memory.limit_in_bytes 文件映射到 /sys/fs/cgroup/memory/docker/<CONTAINER_ID>/memory.limit_in_bytes 来控制容器内 cgroup 层次结构根部的文件,这种方式可以防止容器进程意外地修改宿主机的 cgroup。
但是这种方式有时候会让 cadvisor 和 kubelet 这样的应用感动困惑,因为绑定挂载并不会改变 /proc/<PID>/cgroup 里面的内容。1
2
3
4
5
6
7
8
9$ docker run --rm debian cat /proc/1/cgroup
14:name=systemd:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141
5:memory:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141
4:blkio:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141
3:cpuacct:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141
2:cpu:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141
1:cpuset:/docker/512f6b62e3963f85f5abc09b69c370d27ab1dc56549fa8afcbb86eec8663a141
0::/
cadvisor 会通过查看 /proc/<PID>/cgroup 来获取给定进程的 cgroup,并尝试从对应的 cgroup 中获取 CPU 或内存统计数据。但是由于 Docker Daemon 进程做了绑定挂载,cadvisor 就无法找到容器进程对应的 cgroup。为了解决这个问题,我们在容器内部又做了一次挂载,从 /sys/fs/cgroup/memory 挂载到 /sys/fs/cgroup/memory/docker/<CONTAINER_ID>/(针对所有的 cgroup 子系统),这个方法可以很好的解决这个问题。
现在新的解决方法是使用 cgroup namespace,如果你运行在一个内核版本 4.6+ 的 Linux 系统下面,runc 和 docker 都加入了 cgroup 命名空间的支持。但是目前 Kubernetes 暂时还不支持 cgroup 命名空间,但是很快会作为 cgroups v2 支持的一部分。
IPtables
在使用的时候我们发现在线上的 Kubernetes 集群运行时,有时候容器内的 Docker Daemon 启动的嵌套容器无法访问外网,但是在本地开发电脑上却可以很正常的工作,大部分开发者应该都会经常遇到这种情况。
最后发现当出现这个问题的时候,来自嵌套的 Docker 容器的数据包并没有打到 iptables 的 POSTROUTING 链,所以没有做 masqueraded。
这个问题是因为包含 Docker Daemon 的镜像是基于 Debian buster 的,而默认情况下,Debian buster 使用的是 nftables 作为 iptables 的默认后端,然而 Docker 本身还不支持 nftables。要解决这个问题只需要在容器镜像中切换到 iptables 命令即可。1
2
3RUN update-alternatives --set iptables /usr/sbin/iptables-legacy || true && \
update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy || true && \
update-alternatives --set arptables /usr/sbin/arptables-legacy || true
完整的 Dockerfile 文件和启动脚本可以在 GitHub 上面获取,也可以直接使用 jieyu/dind-buster:v0.1.8 这个镜像来测试。1
$ docker run --rm --privileged jieyu/dind-buster:v0.1.8 docker run alpine wget baidu.com
在 Kubernetes 集群下使用如下所示的 Pod 资源清单部署即可:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20apiVersion: v1
kind: Pod
metadata:
name: dind
spec:
containers:
- image: jieyu/dind-buster:v0.1.8
name: dind
stdin: true
tty: true
args:
- /bin/bash
volumeMounts:
- mountPath: /var/lib/docker
name: varlibdocker
securityContext:
privileged: true
volumes:
- name: varlibdocker
emptyDir: {}
在 Pod 中运行 KinD
上面我们成功配置了 Docker-in-Docker(DinD),接下来我们就来在该容器中使用 KinD 启动 Kubernetes 集群。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20$ docker run -ti --rm --privileged jieyu/dind-buster:v0.1.8 /bin/bash
Waiting for dockerd...
[root@257b543a91a5 /]# curl -Lso ./kind https://kind.sigs.k8s.io/dl/v0.8.1/kind-$(uname)-amd64
[root@257b543a91a5 /]# chmod +x ./kind
[root@257b543a91a5 /]# mv ./kind /usr/bin/
[root@257b543a91a5 /]# kind create cluster
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.18.2) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a nice day! 👋
[root@257b543a91a5 /]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready master 11m v1.18.2
由于某些原因可能你用上面的命令下载不了 kind,我们可以想办法提前下载到宿主机上面,然后直接挂载到容器中去也可以,我这里将 kind 和 kubectl 命令都挂载到容器中去,使用下面的命令启动容器即可:1
$ docker run -it --rm --privileged -v /usr/local/bin/kind:/usr/bin/kind -v /usr/local/bin/kubectl:/usr/bin/kubectl jieyu/dind-buster:v0.1.8 /bin/bash
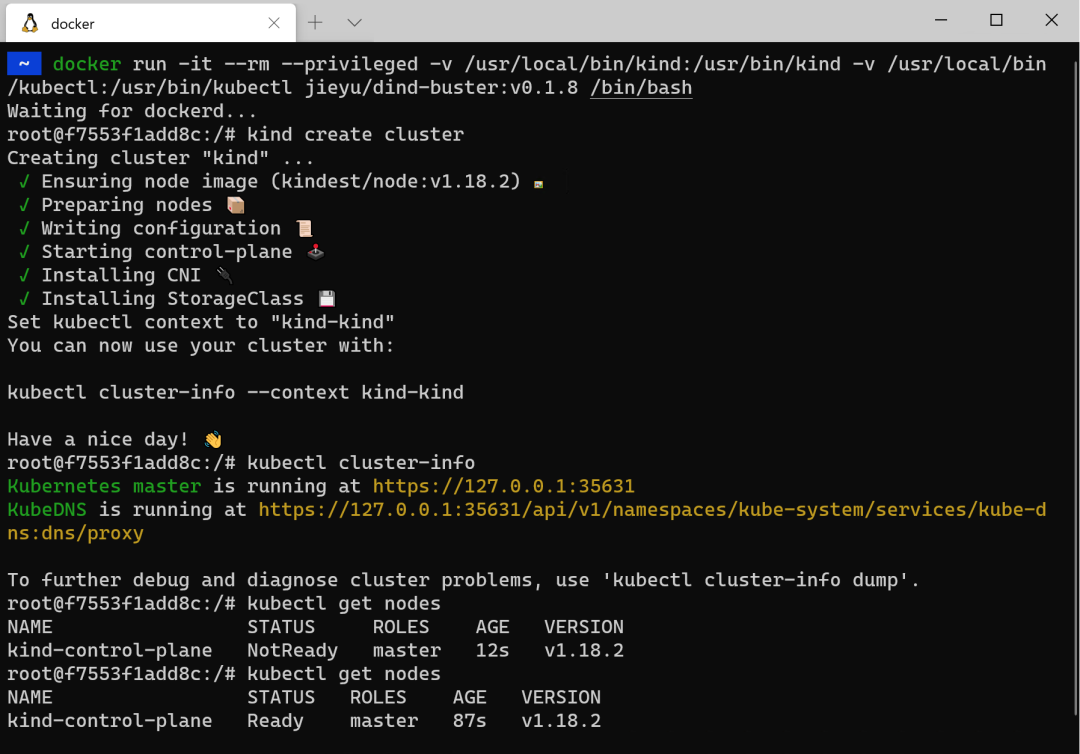
可以看到在容器中可以很好的使用 KinD 来创建 Kubernetes 集群。接下来我们直接在 Kubernetes 中来测试一次:1
2
3
4
5
6
7
8
9
10
11
12$ kubectl apply -f dind.yaml
$ kubectl exec -ti dind /bin/bash
root@dind:/# curl -Lso ./kind https://kind.sigs.k8s.io/dl/v0.7.0/kind-$(uname)-amd64
root@dind:/# chmod +x ./kind
root@dind:/# mv ./kind /usr/bin/
root@dind:/# kind create cluster
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.17.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✗ Starting control-plane 🕹️
ERROR: failed to create cluster: failed to init node with kubeadm: command "docker exec --privileged kind-control-plane kubeadm init --ignore-preflight-errors=all --config=/kind/kubeadm.conf --skip-token-print --v=6" failed with error: exit status 137
我们可以看到在 Pod 中使用 KinD 来创建集群失败了,这是因为在 KinD 节点嵌套容器内运行的 kubelet 会随机杀死顶层容器内的进程,这其实还是和上面讨论的 cgroups 的挂载有关。
但其实我自己在使用 v0.8.1 版本的 KinD 的时候,在上面的 Pod 中是可以正常创建集群的,不知道是否是 KinD 搭建的集群有什么特殊处理,这里需要再深入研究:
如果你在使用的过程中也遇到了上述的问题,则可以继续往下看解决方案。
当顶层容器(DIND)在 Kubernetes Pod 中运行的时候,对于每个 cgroup 子系统(比如内存),从宿主机的角度来看,它的 cgroup 路径是 /kubepods/burstable/<POD_ID>/<DIND_CID>。
当 KinD 在 DIND 容器内的嵌套节点容器内启动 kubelet 的时候,kubelet 将在 /kubepods/burstable/ 下相对于嵌套 KIND 节点容器的根 cgroup 为其 Pods 来操作 cgroup。从宿主机的角度来看,cgroup 路径就是 /kubepods/burstable/<POD_ID>/<DIND_CID>/docker/<KIND_CID>/kubepods/burstable/。
这些都是正确的,但是在嵌套的 KinD 节点容器中,有另一个 cgroup 存在于 /kubepods/burstable/<POD_ID>/<DIND_CID>/docker/<DIND_CID> 下面,相对于嵌套的 KinD 节点容器的根 cgroup,在 kubelet 启动之前就存在了,这是上面我们讨论过的 cgroups 挂载造成的,通过 KinD entrypoint 脚本设置。而如果你在 KinD 节点容器里面做一个 cat /kubepods/burstable/<POD_ID>/docker/<DIND_CID>/tasks,你会看到 DinD 容器的进程。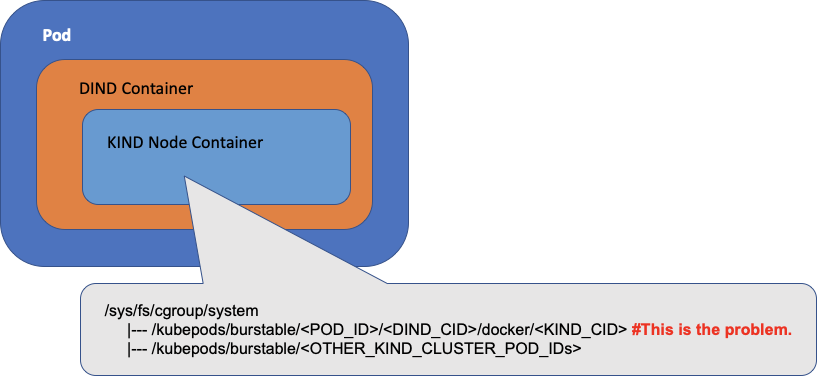
这就是最根本的原因,KinD 节点容器里面的 kubelet 看到了这个 cgroup,以为应该由它来管理,但是却找不到和这个 cgroup 相关联的 Pod,所以就会尝试来杀死属于这个 cgroup 的进程来删除这个 cgroup。这个操作的结果就是随机进程被杀死。解决这个问题的方法可以通过设置 kubelet 的 --cgroup-root 参数,通过该标志来指示 KinD 节点容器内的 kubelet 为其 Pods 使用不同的 cgroup 根路径(比如 /kubelet)。这样就可以在 Kubernetes 集群中来启动 KinD 集群了,我们可以通过下面的 YAML 资源清单文件来修复这个问题。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
apiVersion: v1
kind: Pod
metadata:
name: kind-cluster
spec:
containers:
- image: jieyu/kind-cluster-buster:v0.1.0
name: kind-cluster
stdin: true
tty: true
args:
- /bin/bash
env:
- name: API_SERVER_ADDRESS
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- mountPath: /var/lib/docker
name: varlibdocker
- mountPath: /lib/modules
name: libmodules
readOnly: true
securityContext:
privileged: true
ports:
- containerPort: 30001
name: api-server-port
protocol: TCP
readinessProbe:
failureThreshold: 15
httpGet:
path: /healthz
port: api-server-port
scheme: HTTPS
initialDelaySeconds: 120
periodSeconds: 20
successThreshold: 1
timeoutSeconds: 1
volumes:
- name: varlibdocker
emptyDir: {}
- name: libmodules
hostPath:
path: /lib/modules
使用上面的资源清单文件创建完成后,稍等一会儿我们就可以进入 Pod 中来验证。1
2
3
4$ kubectl exec -ti kind-cluster /bin/bash
root@kind-cluster:/# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready master 72s v1.17.0
同样也可以直接使用 Docker CLI 来进行测试:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20$ docker run -ti --rm --privileged jieyu/kind-cluster-buster:v0.1.0 /bin/bash
Waiting for dockerd...
Setting up KIND cluster
Creating cluster "kind" ...
✓ Ensuring node image (jieyu/kind-node:v1.17.0) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
✓ Waiting ≤ 15m0s for control-plane = Ready ⏳
• Ready after 31s 💚
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Have a nice day! 👋
root@d95fa1302557:/# kubectl get nodes
NAME STATUS ROLES AGE VERSION
kind-control-plane Ready master 71s v1.17.0
root@d95fa1302557:/#
上面镜像对应的 Dockerfile 和启动脚本地址:https://github.com/jieyu/docker-images/tree/master/kind-cluster
下图是我在 KinD 搭建的 Kubernetes 集群中,创建的一个 Pod,然后在 Pod 中创建的一个独立的 Kubernetes 集群最终效果: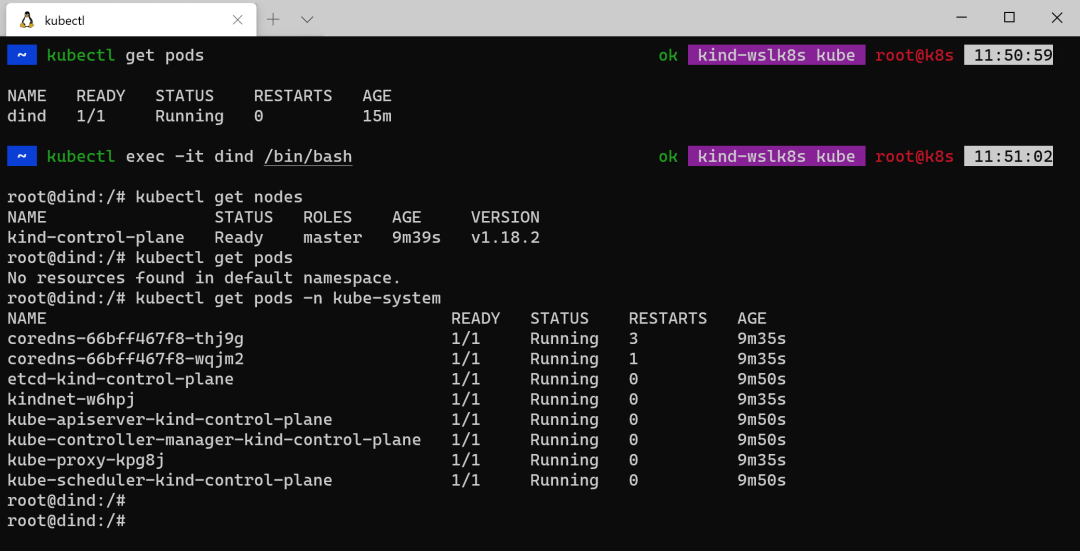
总结
在实现上面功能的时候,过程中还是遇到了不少的障碍,其中大部分都是因为 Docker 容器没有提供和宿主机完全隔离的功能造成的,某些内核资源比如 cgroups 是在内核中共享的,如果很多容器同时操作它们,也可能会造成潜在的冲突。但是一旦解决了这些问题,我们就可以非常方便的在 Kubernetes 集群 Pod 中轻松地运行一个独立的 Kubernetes 集群了,这应该算真正的 Kubernetes IN Kubernetes 了吧~
参考:https://d2iq.com/blog/running-kind-inside-a-kubernetes-cluster-for-continuous-integration