不用重新编译/部署线上程序而是借助 eBPF 即可实现对程序进行调试,接下来我们会用一个系列文章介绍我们是怎么做的,这是开篇。本篇描述了如何使用 gobpf 和 uprobe 来构建一个跟踪 Go 程序函数入口参数变化的应用。这里介绍的技术可以扩展到其它编译型语言,如 C++, Rust 等等。本系列文章后续将会讨论如何使用 eBPF 来跟踪 HTTP/gRPC 数据和 SSL 等等。
介绍
当调试程序时,我们一般对捕获程序的运行时状态非常感兴趣。因为这可以让我们检查程序在干什么,并能让我们确定 bug 出现在程序的哪一块。观察运行时状态的一个简单方式是使用调试器。比如针对 Go 程序,我们可以使用 Delve 和 gdb。
Delve 和 gdb 在开发环境中做调试表现没得说,但是我们一般不会在线上使用此类工具。它们的长处同时也是它们的短处,因为调试器会导致线上程序中断,甚至如果在调试过程中不小心改错某个变量的值而导致线上程序出现异常。
为了让线上调试过程的侵入和影响更小,我们将会探索使用增强版的 BPF (eBPF, Linux 4.x+ 内核可用)和更高级的 Go 库 gobpf 来达成目标。
什么是 eBPF
扩展型 BPF(eBPF) 是一项在 Linux 4.x+ 内核可用的技术。你可以把它看作一个轻量级的沙箱 VM, 它运行在 Linux 内核中并且提供了针对内核内存的可信访问。
就像下面要说的,eBPF 允许内核运行 BPF 字节码。虽然可用的前端(这里指的是编译器前端)语言多样,但通常都是 C 语言的真子集。通常 C 代码先通过 Clang 被编译为 BPF 字节码,然后字节被验证以确保可以安全执行。这些严格的验证保证了机器码不会有意或无意地危及 Linux 内核,同时也确保了 BPF 探针在每次被触发时将会执行有限数目的指令。这些保证确保了 eBPF 可以被用于性能敏感的应用中,比如包过滤,网络监控等等。
从功能上说,eBPF 允许你针对某些事件(如定时器事件,网络事件或是函数调用事件)运行受限的 C 代码。当因为一个函数调用事件被触发时,我们把这些 eBPF 代码叫做探针。这些探针既可以针对内核函数调用事件被触发(这时叫 kprobe, k 即 kernelspace), 也可以针对用户空间的函数调用事件被触发(这时叫 uprobe, u 即 userspace). 本篇文章讲解如何通过 uprobe 实现函数参数的动态追踪。
Uprobes
Uprobes 允许我们通过插入一个 debug trap 指令(在 x86 上就是 int3) 触发一个软中断从而实现对运行在用户空间的程序进行拦截。这也是调试器的工作原理。uprobe 运行过程本质上与其它 BPF 程序一样,可以总结为下面图示: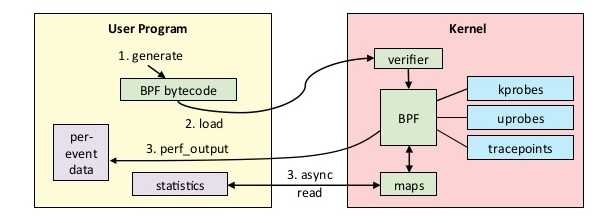
编译和验证过的 BPF 程序作为 uprobe 的一部分被执行,同时执行结果写入到一个 buffer 中。
下面让我们研究下 uprobes 如何起作用的。为了演示部署 uprobes 并捕获函数参数,我们会用到这个简单的 demo 应用。该 demo 相关部分下面介绍。
main() 方法是一个简单的 HTTP server, 它暴露了一个监听 /e 端点的 GET 接口,该接口通过迭代逼近计算自然常数 e(也叫欧拉数). computeE 方法有一个参数 iters, 它指定了逼近时的迭代次数。迭代次数越多,结果越精确,当然耗费 CPU 也越多。迭代逼近算法不是我们本次关注重点,感兴趣的可以自己研究下。我们仅对追踪调用 computeE 方法时的参数感兴趣。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18func computeE(iterations int64) float64 {
res := 2.0
fact := 1.0
for i := int64(2); i < iterations; i++ {
fact *= float64(i)
res += 1 / fact
}
return res
}
func main() {
http.HandleFunc("/e", func(w http.ResponseWriter, r *http.Request) {
// ... 省略代码用于从 get 请求中解析 iters 参数,若为空则使用默认值
w.Write([]byte(fmt.Sprintf("e = %0.4f\n", computeE(iters))))
})
// 启动 server...
}
为了进行后面的实验以及为最后采用 gdb 验证修改生效,我们采用如下指令编译该代码:1
$ go build -gcflags "-N -l" app.go
为了理解 uprobe 如何工作的,我们看看可执行文件中要追踪的符号。既然 uprobes 通过插入一个 debug trap 指令到可执行文件来实现,我们先要确定要追踪的函数地址是什么。Go 程序在 Linux 上的二进制采用 ELF 格式存储 debug 信息,该信息甚至在优化过的二进制中也是存在的,除非 debug 数据被裁剪掉了。我们可以使用命令 objdump 来检查二进制文件中的符号:1
2
3
4
5# 执行下面命令之前需要你先将上面 go 程序编译为名为 app 的二进制文件。
# objdump --syms 可以从可执行程序中导出全部符号,然后通过 grep 查找 computeE.
# 具体输出可能与你机器上不同,这没什么问题。
$ objdump --syms app | grep computeE
00000000000x6600e0 g F .text 000000000000004b main.computeE
从上述输出可以看到,computeE 方法的入口地址为 0x0x6600e0. 为了看一下这个地址附近的指令,我们可以通过 objdump 来反汇编该二进制文件(通过命令行选项 -d). 反汇编代码如下:1
2
3$ objdump -d app | grep -A 1 0x6600e0
00000000000x6600e0 <main.computeE>:
0x6600e0: 48 8b 44 24 08 mov 0x8(%rsp),%rax
从上面汇编代码可以看到当 computeE 方法被调用时会执行哪些指令。第一条指令是 mov 0x8(%rsp),%rax, 该指令将寄存器 rsp 保存的地址(栈指针寄存器保存的是 computeE 方法的入口地址)相对偏移量为 0x8 处的内容移动到寄存器 rax 中。这个被移动的值即为 computeE 方法的入参 iterations 的值。Go 程序的参数通过栈来传递。
好了,记住上面提到的信息,我们来看看如何实现针对 computeE 方法的参数追踪。
构建追踪程序
我们给这个追踪程序起个名叫 Tracer. 为了捕获前面提到的事件,我们需要注册一个 uprobe 函数,并且还得有个用户态函数负责去读 uprobe 的输出,具体如下图所示: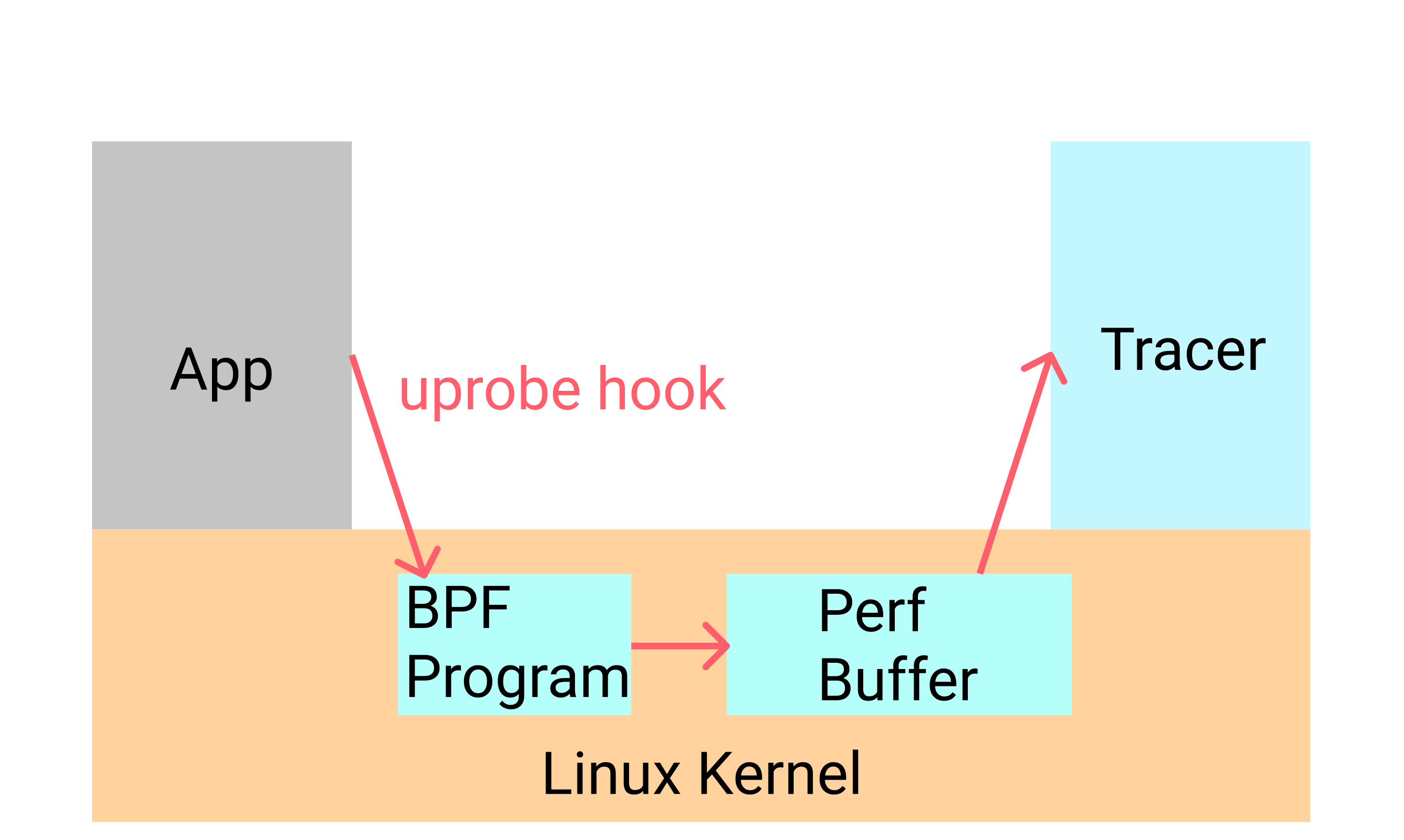
我们编写一个叫做 tracer 的应用,由它负责注册 BPF 代码,同时读取这些 BPF 代码的输出。如上图所示,uprobe 将会简单地输出到一个 perf-buffer 中,该结构体是用于 perf 事件的 linux 内核数据结构。
万事俱备,我们来看看当我们增加一个 uprobe 时会发生哪些事情。下面的图显示了 Linux 内核如何使用一个 uprobe 来修改一个已有的二进制程序。前文提到的软中断 int3 作为第一条指令被插入到 main.computeE 方法中。这条指令将会在执行时触发一个软中断,从而允许 Linux 内核来执行 BPF 代码。然后我们把 computeE 每次被调用时的参数输出到 perf-buffer 中,这些值会被我们编写的 tracer 应用异步地读取。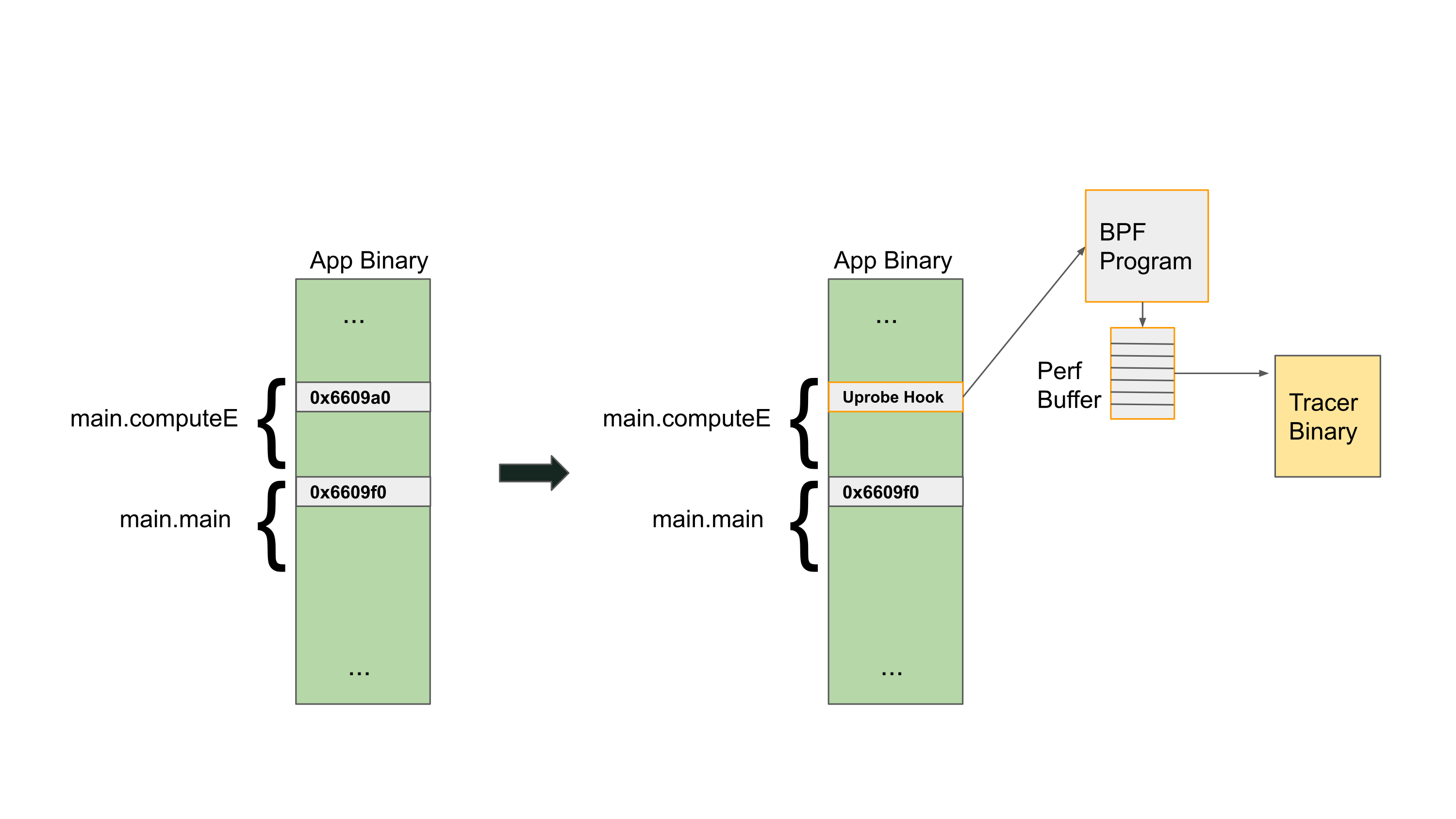
就我们这个需求来说,相应的 BPF 代码很简单,C 代码如下:1
2
3
4
5
6
7
8
9
BPF_PERF_OUTPUT(trace);
// 该函数将会被注册,以便每次 main.computeE 被调用时该函数也会被调用
inline int computeECalled(struct pt_regs *ctx) {
// main.computeE 的入参保存在了 ax 寄存器里。
long val = ctx->ax;
trace.perf_submit(ctx, &val, sizeof(val));
return 0;
}
我们注册上面代码以便 main.computeE 方法被调用它们也会被执行。这些代码被执行时,我们仅仅读取函数参数然后写到 perf-buffer 中。实现这个功能需要很多样板代码,为了方便示意这里都省掉了,完整的例子见 这里.
好了,我们现在有个针对 main.computeE 的功能齐全的端到端参数追踪器了!执行结果见下面动图: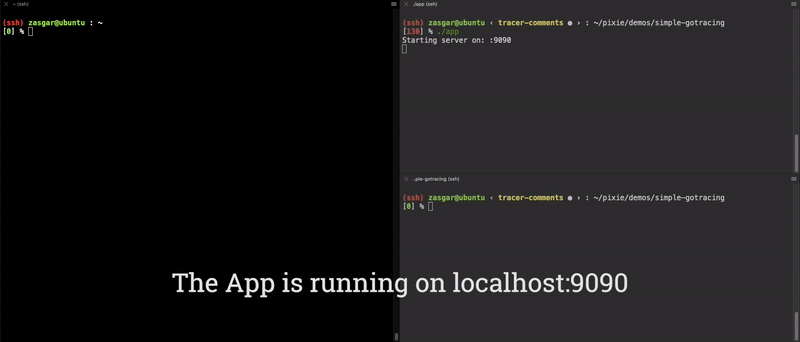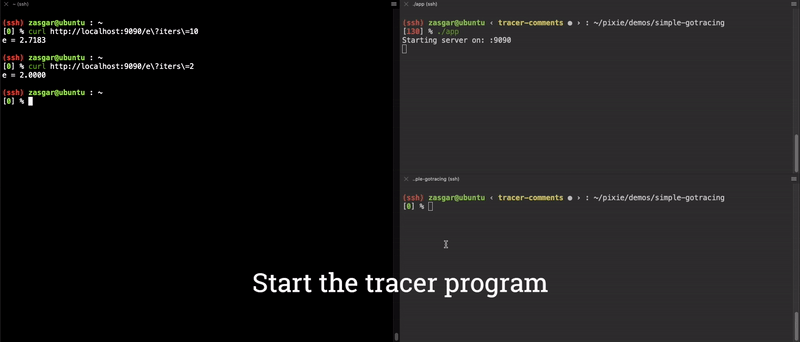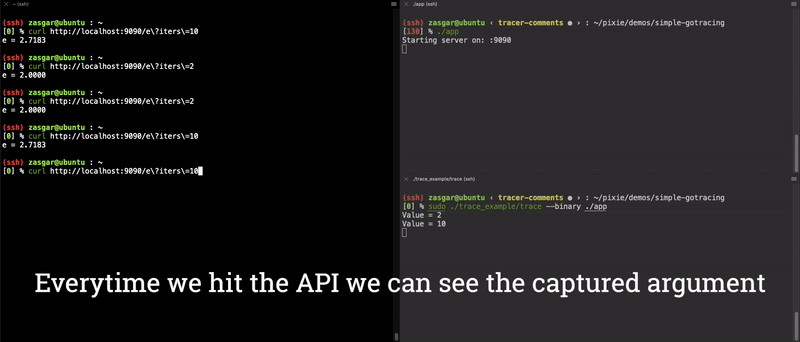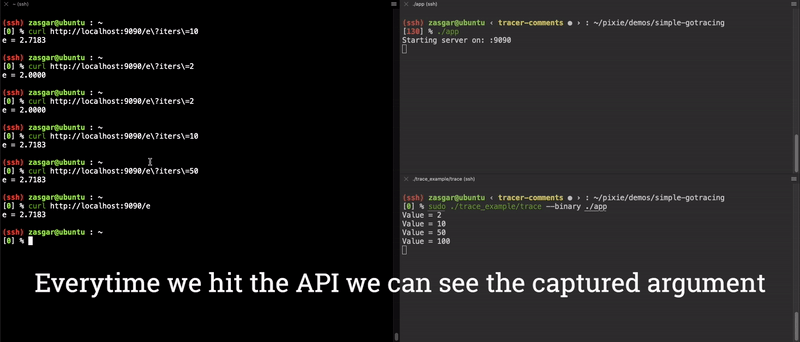
上述动图执行步骤如下:
- 在 localhost:9090 启动待追踪程序
./app, 此时我们可以用 curl 访问该应用了,具体命令为curl http://localhost:9090/e?iters=10 - 启动 trace 应用,注意指定参数
sudo ./trace --binary ../app/app, 参数是第一步中待追踪程序对应的二进制文件的路径。 - 不停的执行 curl 命令,使其 iters 参数取值不同,则会看到 trace 应用输出你指定的 iters 值。
还有个有意思的事情,我们真的可以通过 GDB 看到针对二进制文件的修改。下面我们 dump 出 0x0x6600e0 处的指令,在我们运行 trace 之前是这样的:1
2
3
4
5
6
7$ gdb ./app
(gdb) display /4i 0x6600e0
1: x/4i 0x6600e0
0x6600e0 <main.computeE>: sub $0x20,%rsp
0x6600e4 <main.computeE+4>: mov %rbp,0x18(%rsp)
0x6600e9 <main.computeE+9>: lea 0x18(%rsp),%rbp
0x6600ee <main.computeE+14>: xorps %xmm0,%xmm0
在我们运行 trace 之后,再次查看:1
2
3
4
5
6
7$ gdb ./app
(gdb) display /4i 0x65fecf
2: x/4i 0x6600e0
0x6600e0 <main.computeE>: int3
0x6600e1 <main.computeE+1>: sub $0x20,%esp
0x6600e4 <main.computeE+4>: mov %rbp,0x18(%rsp)
0x6600e9 <main.computeE+9>: lea 0x18(%rsp),%rbp
看到了吗?0x6600e0 插入了 int3 指令。
尽管我们为这个特定的示例硬编码了跟踪程序,但是可以使这个过程通用化。Go 的许多特性,比如嵌套的指针、接口、通道等,使得这个过程具有挑战性,但解决这些问题可实现现有系统中无法使用的另一种检测模式。而且,由于这个过程是在二进制层面工作的,所以它可以用于其他语言编译的二进制文件 (c++、Rust 等)。我们只需要考虑他们各自 ABI 的差异。
接下来?
使用 uprobes 进行 BPF 跟踪具有其自身的优点和缺点。当我们需要对二进制状态进行观察时,使用 BPF 是有益的,即使在附加调试器将会有问题或有害的环境中运行(例如,生产二进制文件)。最大的缺点是,即使是很小的应用程序状态的跟踪也需要去编写代码。虽然 BPF 代码是相对容易的,但它的编写和维护是复杂的。如果没有实际的高级工具,就不太可能将其用于通用调试。
番外
安装 BCC
编译前文提到的 trace 应用之前需要安装 bcc. 以 Ubuntu 16.04 为例(其它系统请参考 这里):1
2
3
4sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 4052245BD4284CDD
echo "deb https://repo.iovisor.org/apt/$(lsb_release -cs) $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/iovisor.list
sudo apt-get update
sudo apt-get install bcc-tools libbcc-examples linux-headers-$(uname -r)
如果安装速度慢,而且你设置了 http_proxy/https_proxy, 请编辑 /etc/sudoers 新增一行 Defaults env_keep = "http_proxy https_proxy", 这样速度至少会有百倍提升。
too many arguments 编译错误
1 | # github.com/iovisor/gobpf/bcc |
原因为 这一行 增加的特性 Update bcc_func_load to libbcc 0.11 with hardware offload support, 以及 这一行 增加的特性 bcc: update bpf_module_create_c_from_string for bcc 0.11.0 (fixes #202).
我没有深究具体是什么导致的(初步怀疑是系统版本), 如果你急着看结果,可以根据上面报错地址知道到 module.go 文件,把涉及的两个函数的最后一个 nil 参数去掉就可以顺利编译了。
本文翻译自:Debugging Go in prod using eBPF 作者:Zain Asgar