概述
对于许多 Go 开发人员来说,系统地使用指针来共享结构体而不是拷贝本身似乎是性能方面的最佳选择。
为了理解使用指针而不是拷贝结构体的影响,我们将回顾两个用例。
用例1:数据密集分配
让我们举一个简单的例子,当你想共享一个结构体的值:1
2
3
4
5type S struct {
a, b, c int64
d, e, f string
g, h, i float64
}
这是一个基本的结构体,可以通过拷贝或指针共享:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func byCopy() S {
return S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
func byPointer() *S {
return &S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
基于这两种方法,我们现在可以编写两个基准测试,其中一个是通过拷贝结构体传递的:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24func BenchmarkMemoryStack(b *testing.B) {
var s S
f, err := os.Create("stack.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byCopy()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
另一个,非常相似,通过指针传递:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24func BenchmarkMemoryHeap(b *testing.B) {
var s *S
f, err := os.Create("heap.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byPointer()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
让我们运行一下基准测试:1
2go test ./... -bench=BenchmarkMemoryHeap -benchmem -run=^$ -count=10 > head.txt && benchstat head.txt
go test ./... -bench=BenchmarkMemoryStack -benchmem -run=^$ -count=10 > stack.txt && benchstat stack.txt
以下是统计数据:1
2
3
4
5
6
7
8
9
10
11
12
13name time/op
MemoryHeap-4 75.0ns ± 5%
name alloc/op
MemoryHeap-4 96.0B ± 0%
name allocs/op
MemoryHeap-4 1.00 ± 0%
------------------
name time/op
MemoryStack-4 8.93ns ± 4%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
在这里使用结构的拷贝而不是指针要快 8 倍。
为了理解其中的原因,让我们来看一下 trace 生成的图表: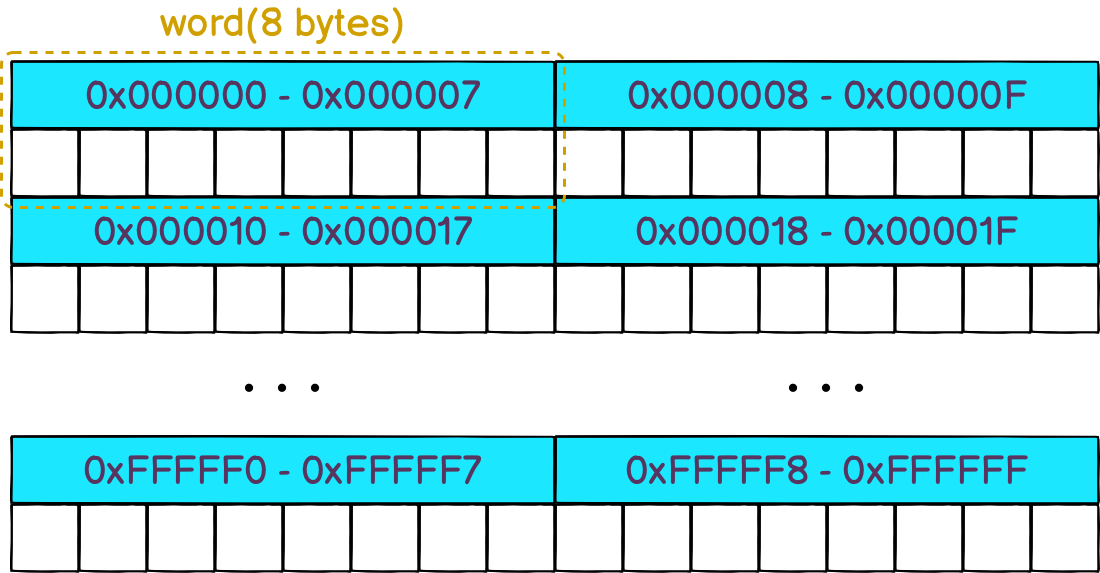
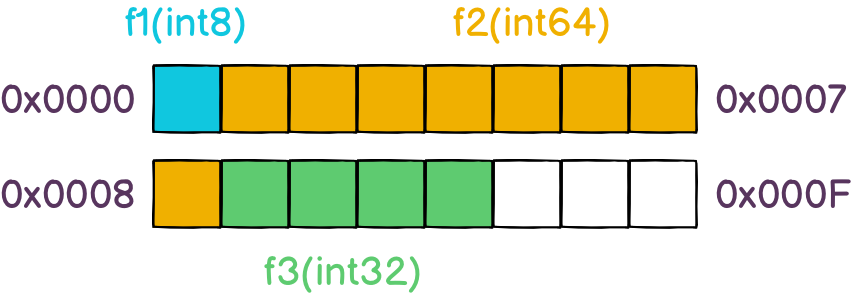
第一个图很简单。由于没有使用堆,因此没有垃圾回收器和额外的 goroutine。
对于第二个图,指针的使用迫使 go 编译器将变量转义到堆中,并对垃圾回收器施加压力。如果我们放大这个图,我们可以看到垃圾回收器在这个过程中扮演了重要的角色: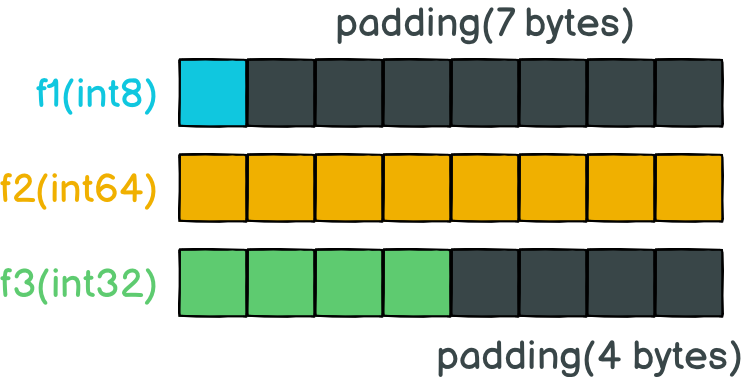
从这个图中我们可以看到,垃圾回收器必须每 4ms 工作一次。
如果我们再次放大,我们可以得到正在发生的事情的详细信息:
蓝色、粉色和红色的是垃圾回收器的阶段,而棕色的阶段与堆上的分配有关(在图表上标记为 “runtime.bgsweep”):
扫描是指回收与堆内存中未标记为正在使用的值相关联的内存。当应用程序
Goroutines试图在堆内存中分配新值时,就会发生此活动。扫描的延迟会增加在堆内存中执行分配的成本,并且不会与垃圾回收相关的任何延迟相关联。
https://www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
即使这个示例有点极端,我们也可以看到在堆上分配变量而不是在栈上分配变量的代价有多大。在我们的示例中,代码在栈上分配结构体并拷贝它比在堆上分配结构体并共享其地址要快得多。
如果您不熟悉栈/堆,如果您想了解更多关于每个堆的内部细节,您可以在网上找到许多资源,比如 Paul Gribble 的这篇文章。
如果我们将 GOMAXPROCS=1 的处理器限制为 1,情况会更糟:1
2
3
4
5
6
7
8
9
10
11
12
13name time/op
MemoryHeap 114ns ± 4%
name alloc/op
MemoryHeap 96.0B ± 0%
name allocs/op
MemoryHeap 1.00 ± 0%
------------------
name time/op
MemoryStack 8.77ns ± 5%
name alloc/op
MemoryStack 0.00B
name allocs/op
MemoryStack 0.00
如果在栈上有分配的基准没有改变,那么在堆上的基准已经从 75ns/op 降低到 114ns/op。
用例2:密集的函数调用
对于第二个用例,我们将在结构体中添加两个空方法,稍微调整一下我们的基准用例:1
2func (s S) stack(s1 S) {}
func (s *S) heap(s1 *S) {}
在栈上分配的基准测试将创建一个结构并通过拷贝传递它:1
2
3
4
5
6
7
8
9
10
11
12func BenchmarkMemoryStack(b *testing.B) {
var s S
var s1 S
s = byCopy()
s1 = byCopy()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.stack(s1)
}
}
}
而堆的基准测试将通过指针传递结构体:1
2
3
4
5
6
7
8
9
10
11
12func BenchmarkMemoryHeap(b *testing.B) {
var s *S
var s1 *S
s = byPointer()
s1 = byPointer()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.heap(s1)
}
}
}
不出所料,结果现在大不相同:1
2
3
4
5
6
7
8
9
10
11
12
13name time/op
MemoryHeap-4 301µs ± 4%
name alloc/op
MemoryHeap-4 0.00B
name allocs/op
MemoryHeap-4 0.00
------------------
name time/op
MemoryStack-4 595µs ± 2%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
结论
在 go 中,使用指针而不是拷贝结构体并不总是一件好事。
为了你的数据选择好的语义,我强烈建议阅读 Bill Kennedy 写的关于值/指针语义的文章。它将让您更好地了解结构和内置类型可以使用的策略。
此外,对内存使用情况的分析肯定会帮助您了解在分配和堆上发生了什么。